Olen jonkin aikaa pohtinut sitä, että miksi eri ohjelmointikielillä on eri syntaksia samaan toiminallisuuteen, kuten esimerkiksi auto vs let tai def fun_name vs fun_name.
No sitten ajattelin, että eikö olisi kivaa, jos voisi kirjoittaa eri abstraktion kieliä samantyyppisellä syntaksilla.
Esimerkiksi:
C++:
return_type function_name( parameter list ) {
body of the function;
return val_of_return_type;
}ja Python:
def function_name( parameter list ):
body of the function
return val_of_some_typeYhdistettäisiin siten, että C++ pysyy samana, mutta "C++-Python:ia" voisi kirjoittaa:
function_name( parameter list )
body of the function
return val_of_some_typeTämä on käytännössä suurinpiirtein C++:n ja Python:n leikkaus (intersection).
Näin Python:iin siirryttessä oleellista on, että bracketit poistuivat ja whitespace on käytössä sekä että return antaa palauttaa mitä tyyppiä vain, koska Python on dynaaminen. "def" (ja semicolonit) tulkittiin redundantiksi syntaksiksi, ja ilman sitä Python muistuttaa enemmän C++:aa, mutta muutettuna "oleellisin osin", jotta Python:in edut näkyvät.
Joku varmaan yrittäisi tälle jotain tulkkeja tms., mutta ajattelin, että miksi tämmöistä ei voisi toteuttaa staattisena analysaattorina, jolle vaan annetaan sinun hybridikieliset tiedostot ja joka lisää tai poistaa syntaksia. Eli kun C++-Python -ohjelma annetaan sille, niin se osaisi lisätä snippetiin def:n, jotta koodi kääntyy nykyisillä Python-kääntäjillä.
---
Yleisiä vasta-argumentteja:
"Tämä pilaa kielen X puhtaan syntaksin"
Koska kaikilla kielillä on omasta mielestään paras ja puhtain syntaksi ja silti kielet eivät ole samalla syntaksilla, niin parhaaksi voi mieltää myös näiden kaikkien yhdistelmän tai leikkauksen, erityisesti sekakielisissä projekteissa.
Yksi kompastuskivi voi olla, että esim. "def" ei ole oikeasti ihmisille tarkoitettu, vaan sen funktio on signaloida kääntäjälle/tulkille, että mikä on funktion määritelmä ja mikä on jotain muuta.
Tällöinkin tietysti sen voisi lisätä koneellisesti, mutta on eri asia, että voiko kirjoittaa sellaista analysaattoria, joka osaa tunnistaa paikat "def":lle.
Naiivisti oletan, että esim.:
function_name( parameter list )
body of the function
return val_of_some_typesekoittuu ekalla rivillä funktiokutsuun, joten sen selvittäminen funktioksi vaatii whitespacen tulkkaamisen ja lopun "return"-lauseen löytämisen.
Toisaalta tälle voisi ehkä tehdä jonkin metakielen, jossa funktio-block merkataan kaikissa muokattavissa kielissä esimerkiksi:
#function
#/function
tai
#begin function
#end function
Eli esimerkiksi:
#function
function_name( parameter list )
body of the function
return val_of_some_type
#/functionNyt ensimmäisen rivin (ellei se ole kommentti) on pakko olla funktion määritelmä.
Java:ssa esim.:
#function[public]
int function_name(int a) {
body of the function;
return val_of_int;
}
#/function[public]Tässä huomattiin, että kun eri kielissä on myös eri syntaksi scopeille. Muilta osin tämähän näyttää C/C++:lta.
Ihanko tosissasi meinaat, että joku kirjoittaa mielummin:
#function ... #/function
Meinaatko, että tuo säästää paljonkin aikaa sen sijaan, että vaan kirjoittaisi sanan "def"? ;D
En muutenkaan ymmärrä fetissiäsi C:n syntaksiin.
jalski kirjoitti:
Ihanko tosissasi meinaat, että joku kirjoittaa mielummin:
#function ... #/functionMeinaatko, että tuo säästää paljonkin aikaa sen sijaan, että vaan kirjoittaisi sanan "def"? ;D
Arvasin, että joku tarttuu tuohon, mutta ohitit sen, että metakieli on sama _kaikille kielille_. Se siis poistaa tarpeen muistaa se, miten eri kielissä tehdään ko. asia, ja antaa käyttää kaikille kielille yhtenäistä syntaksia. Kirjoitamme siis kaikissa hybridikielissä #function ja #/function.
Joudut ehkä kirjoittamaan joissain tapauksissa enemmän merkkejä, mutta säästät sen, ettei sinun tarvitse muistaa kunkin kielen omaa tapaa tehdä ko. asia, vaan riittää, että muistat metakielen ja "C-variantin", joka on usein helppo päätellä.
jalski kirjoitti:
En muutenkaan ymmärrä fetissiäsi C:n syntaksiin.
Se on suurin yhteinen nimittäjä. Esimerkiksi Python:in helppo muokattavuus hybridikieleksi on osoitus tästä.
Tietysti hybridikieliä voi tällä tehdä myös muihin suuntiin, mutta ajattelin, että C/C++:n ollessa melkein kaikessa alin nimittäjä projektin päätavoite olisi sen säilyttäminen ylemmän abstraktion kieliin.
Näin saamme esimerkiksi stackista:
C/C++ - Java - Python - JavaScript
variantin
C/C++ - "C++-Java" - "C++-Python" - "C++-JavaScript"
Ja koska kyseessä on staattinen analyysi, niin mihinkään nykyisiin kääntäjiin tms. ei tarvitse koskea.
mavavilj kirjoitti:
Se on suurin yhteinen nimittäjä. Esimerkiksi Python:in helppo muokattavuus hybridikieleksi on osoitus tästä.
Miksi ihmeessä Python kehittäjä haluaisi vaihtaa ilmaisukykyisemmän ohjelmointikielen syntaksin C:n kankeaan syntaksiin?
jalski kirjoitti:
mavavilj kirjoitti:
Se on suurin yhteinen nimittäjä. Esimerkiksi Python:in helppo muokattavuus hybridikieleksi on osoitus tästä.
Miksi ihmeessä Python kehittäjä haluaisi vaihtaa ilmaisukykyisemmän ohjelmointikielen syntaksin C:n kankeaan syntaksiin?
Syy tämän projekti-idean postaamiseen oli saada tämä näkemys. Ymmärrän sen, että Python-syntaksilla on arvoa pelkästään Python-kehittäjille, eikä tämä projekti muutakaan sitä lainkaan.
Projekti vaan kysyy sitä, että onko hybridikielistä arvoa "sekakieli"-devaajille. Niiden etu on, että tällöin kaikki kielet näyttävät oleellisilta osiltaan samalta ja oleellisilta parannuksiltaan erilaisilta, riippumatta siitä, että millä ne käännetään. Tämä on kuin Java:n WORA; mutta sovellettuna eri asiaan. Learn Once Write Anything tai Write Once Be Anything, kun huomataan, että esim. staattisesti tyypitetystä metakieliohjelmasta pääsee helposti dynaamiseen vaan muuttamalla tyypit.
Esimerkiksi "C++-Python" -syntaksiin pääsee muistamalla, että "Python on dynaaminen ja siinä käytetään whitespacea lukemisen helpottamiseksi" (<- oleelliset parannukset), kaikki muu säilyy. Ei tarvitse muistaa, että miten se funktio määriteltiin yms.
Suurimman osan ohjelmointikielten syntakseista oppii viikonlopussa sille tasolle, että pystyy sillä työskentelemään.
Miten esimerkiksi miettimäsi hybridi syntaksi suoriutuisi seuraavasta PL/I-ohjelmointikielellä mahdollisesta toistorakenteesta?
do k = 1 to 10, 9 to 1 by -1, 2 repeat 2*i while (i <= 1024); ... end;
jalski kirjoitti:
(02.04.2024 13:53:37): Suurimman osan ohjelmointikielten...
Avaa ensin, miten tuo jäsentyy, koska en osaa PL/I-kieltä. Lisäksi minusta täällä ei ole tuota konstruktiota: https://www.ibm.com/docs/en/wdfrhcw/1.4.0?topic=commands-do-command-pli
Onko esim. k:ta kaksi muuttujaa? Onko se tuple vai jotain muuta?
Suoritetaanko do ennen repeat:ia? Ovatko ne itsenäisiä?
Oleellista on, että tuolle pitäisi muotoilla vastaava C/C++ -looppi, ja miettiä, että voiko sen ja tuon yhdistää.
Tämä tosin alleviivaa esimerkin, että kaikissa tapauksissa hybridikielestä ei välttämättä ole etua. Siitä voi olla etua "sekakieli"-projekteissa, mutta PL/I ei näytä siltä, että sitä edes käytettäisiin C-kielten kanssa.
Metakieli tosin antaisi tehdä myös toisinpäin. Eli jos esimerkiksi mielestäsi PL/I:n syntaksi tuohon kyseiseen kohtaan on parempi, niin voisit käyttää tuota osaa C++-ohjelmassa. Analysaattori vaihtaisi PL/I -loopin C++ -loopiksi.
Metakielen voitto on siis sama kuin DSL:ien yleensä. Mutta se painottaa sitä, että kaikkien käytettyjen kielien joukkojen leikkaus on samaa.
Minusta myös syntaksit oppii sinänsä nopeasti, mutta on haastavaa muistaa jokaisen kielen "nyansseja", jos käyttää monia kieliä.
Potentiaalisesti metakieli voisi helpottaa myös muita polkuja, kuten vaikkapa kääntäjien tehostamista yms.
Yksi keksimäni sovellusalue on Android-ohjelmointi niille, joiden pääasiallinen intressi on NDK, ja joiden rasitteena on Java SDK, jota he eivät sinänsä haluaisi käyttää.
Kyseisellä analysaattorilla olisi hypoteettisesti mahdollista kirjoittaa JNI:n Java-puoli "C++-Java:lla", joka ehkä toimisi "middle-ground":ina Androidilla oleville pääasiassa C/C++ -kehittäjille. Koska näitä kehittäjiä ei oikeasti kiinnosta Java:n syntaksi lainkaan.
Toimii toiseenkin suuntaan eli jos olet Java-ohjelmoija ja sinua rasittaa NDK:n C/C++ ja toivoisit, että sitä voisi tuottaa enemmän kuin Java:aa.
Myös WebView on vähän rasittava, koska jos JS:llä tekee jotain muuta kuin DOM:ia, niin ainakin itse toivon, että se muistuttaisi enemmän C:tä.
Staattisena analysaattorina tämä ei voi myöskään tuottaa käännösvirheitä, toisin kuin transpilerit.
Olen kuullut, että on tehty projekteja, missä kieleen on tehty erilaisia laajennuksia kommentteihin. Nämä sitten käännetään erillisellä ohjelmalla, joka tuottaa toimivaa ohjelmakoodia, jonka voi sitten kääntää tai ajaa. Katso https://trac.cc.jyu.fi/projects/comtest/wiki/
Jos kielistä löytyy myös osia, jotka ovat samankaltaisia tai itse kielet ovat strukturaalisesti samankaltaisia, niin on mahdollista, että analysaattori voisi tehdä myös source-to-source -käännöksen, mikäli siis ainoat puuttuvat asiat molemmissa kielissä ovat sellaisia, jotka analysaattori lisää. Python <-> JS luulisi onnistuvan johonkin asti.
Muita käyttöesimerkkejä:
taulukot, listat ja vektorit yms. voitaisiin pakata yhden syntaksin alle, ja tuottaa analysaattorilla kohdekielen oikea syntaksi.
yleisille standardikirjastofunktioille voisi olla myös vain yksi syntaksi.
Tämä on vähän niinku https://haxe.org/, mutta ilman kääntämistä.
Potentiaalisesti tämänkaltainen työkalu on parempi kuin Haxe joissain tapauksissa, kuten:
"Generated source code tends to be rather verbose. The HelloWorldexample up above generated 15 lines of Python for what could be done in two, and 102 lines of C++."
https://peterfraedrich.medium.com/haxe-the-good-the-bad-and-the-ugly-bdb6bdbdb23e
Koska kuten ilmaistu:
class HelloWorld {
public static function main() : Void {
trace('Hello world!');
}
}Olisi metakielellä:
#class
HelloWorld {
#function[public,static]
void main() {
print('Hello world!');
}
#/function
}
#/classTJSP.
Josta voi päätellä, että C++ -versio (ja Java myös!) on itseasiassa täysin sama:
#class
HelloWorld {
#function[public,static]
void main() {
print('Hello world!');
}
#/function
}
#/class(ehkä string-tyypillä pitäisi tehdä jotain muutakin)
Joten esimerkiksi nyt ei tarvitsi tietää, miten Haxe/C++/Java käännetään tai suoritettaan, kun annettais vaan analysaattorin tehdä se.
Pythoniin täydennettäessä vähän hankaluuksia, kun tulisi:
class HelloWorld:
@staticmethod
def main(args):
print("Hello world!")mutta tämä ei vielä printaa mitään käännettäessä.
Optiona nähdään jo, että staattisesti tyypitetystä voidaan kääntää suoraan dynaamiseen (tyypit vain pudotetaan pois).
Erona kaikkiin muihin kieliin on, että metakieli itseasiassa sallii kirjoittaa samanaikaisesti staattisesti tyypitettyä ja dynaamisesti tyypitettyä kunhan ne muunnetaan niitä vastaaviin kieliin.
Näin metakielessä voidaan esimerkiksi kirjoittaa toisiinsa liittyvät asiat samaan tiedostoon ja samaan kohtaan ja toteuttaa käännökset vain ajoa varten.
Metakieli sallisi siis esimerkiksi C++:n ja Python:n sekoittamisen samassa tiedostossa, kunhan vastaavat tekstilohkot päätyvät .h/.cpp tai .py tiedostoiksi.
Tämän voi myös mieltää eräänlaiseksi semanttiseksi kieleksi, koska tämä "markupaa" kaikki yhteensopivat kielet siten, että niiden ohjelmista voi selvittää esimerkiksi funktioiden määrän yms.
Metakielessä on potentiaalisesti se etu, että se voidaan myös luoda mille sopivalle alustalle tahansa, mutta prototyyppi on metakielellä.
Metakielessä ei siis välttämättä tarvitse lyödä lukkoon tyypitystä.
Eräs laajempi ideani oli myös sallia GC ja non-GC -koodi samassa tiedostossa, mutta en ole varma onnistuuko tämä. Käytännössä kuitenkin jo C++:n ja Java:n (yllä jo näytettiin, että niiden Hello World -syntaksi on sama) saa joiltain osin samaan tiedostoon.
Mutta esim.:
#newobject int Array arr = new Array(10); #/newobject
voisi tuottaa sekä C:n int-arrayn tai Java:n vektorin.
Eli esimerkiksi C:n esimerkki:
int *arr = malloc(10 * sizeof(int)); ... free(array);
Tässä olisi jo vaikeutena kuitenkin tietää, mihin kohtaan lätkäistä free.
Java:
int arr[] = new int[10];
Tässä on nyt esimerkiksi se etu, että meidän ei tarvitse tietää, mikä konstruktio vastaa mitäkin, vaan voimme kirjoittaa new Vector, joka toteuttaa kohdekielen vektoriluokan tms.
Voisimme siten myös esimerkiksi valita haluamamme indeksoinnin, kunhan se on määritelty metakielessä.
arr[0]
vai
arr[1]
vai
arr.get(1)
vai
...
Metakieli siis sisällyttäisi myös 0-pohjaisen indeksoinnin vaihtamisen 1-pohjaiseen, mikä on usein toteutettu kirjastolla kohdekieleen.
Koska Haxe on avoimella lisenssillä, niin tämän voisi ehkä liittää sen osaksi, kuten:
https://haxe.org/manual/std.html
Haxe:lla on enemmänkin etuja kuin esim. Javalla.
Miksi koodin kirjoittamisen "tyylillä" on väliä? C++-koodia ei suoriteta sellaisenaan vaan se käännetään ensin käyttöjärjestelmän / suorittimen ymmärtämään muotoon. Python-koodiakaan ei suoriteta sellaisenaan vaan tulkki kääntää sen ensin tavukoodiksi.
Eikö olisi paljon mukavampaa, jos voisit kirjoittaa koodia millä kielellä tahansa, oman makusi mukaan, ja se toimisi yhdessä toisella kielellä kirjoitetun koodin kanssa? No ei tietenkään, koska sinähän inhoat JVM:ää.
muuskanuikku kirjoitti:
(05.04.2024 08:13:07): Miksi koodin kirjoittamisen "tyylillä" on...
Koska tämä pitäisi saada ilman virtuaalikonetta ja roskienkeruuta.
muuskanuikku kirjoitti:
Eikö olisi paljon mukavampaa, jos voisit kirjoittaa koodia millä kielellä tahansa, oman makusi mukaan, ja se toimisi yhdessä toisella kielellä kirjoitetun koodin kanssa? No ei tietenkään, koska sinähän inhoat JVM:ää.
No tämä oli tämän metakielen idea.
Mutta https://fusion-lang.org/ tulee lähelle. Siinä ei vaan voi valita syntaksia. Tai voi sinänsä. Siirtymällä kohdekielen lähdekoodiin.
Yllä olevan PL/I -esimerkin innoittamana ajattelin, että mitä jos haluaisi kirjoittaa:
#class
HelloWorld {
#function[public,static]
void main() {
#loop.PLI
DO i = 1 REPEAT 2*i UNTIL (i = 256); END;
#/loop.PLI
}
#/function
}
#/classLisäksi keksin jo, että lukemisen helpottamiseksi #-lauseet pitäisi saada piilotettua halutessa. Jolloin tämä on:
HelloWorld {
void main() {
DO i = 1 REPEAT 2*i UNTIL (i = 256); END;
}
}Kysymys on, että mitä tuolla PL/I-lauseella pitäisi tehdä? Tuottaa siitä PL/I "moduuli", ajaa se ja antaa paluuarvo tälle ohjelmalle? Vai tulkata PL/I lause esim. C:ksi?
Fusion tai Haxe eivät ole kuten tämä muuten.
Haxe:ssa ongelmana on, että käännöksen tuottama lähdekoodi on lukukelvotonta, vaikka se toteuttaisikin toimivan ohjelman.
Fusion:ssa käännöksen tuottama koodi on luettavaa, mutta Fusion:n tarkoitus on tuottaa kirjastoja kohdekieliin, eikä olla ohjelmointikieli sinänsä. Lisäksi se sallii epätriviaalisti vaihtoehtoiset syntaksit.
Oman kielen suunnittelu ja toteuttaminen on todella opettavaista. Onnea matkaan.
jlaire kirjoitti:
Oman kielen suunnittelu ja toteuttaminen on todella opettavaista. Onnea matkaan.
En minä tätä sen takia pohtinut, vaan koska tämän tulisi olla helpompaa kuin esimerkiksi C/C++ + Java/Kotlin monikieliprojekti.
Myös olen jo todennut, että tämä on lopulta lyhyempää tai ei paljoa monisanaisempaa kuin esimerkiksi Ruby:n FFI-koodi:
floor = Fiddle::Function.new( libm['floor'], [Fiddle::TYPE_DOUBLE], Fiddle::TYPE_DOUBLE )
Mutta FFI:tä käytelleenä olen sitä mieltä, että se, että monikielikoodista toteutetaan moduuleja on varmasti yksinkertaisempaa kuin FFI. Eli että esim. yo. PL/I rivi on PL/I-moduuli.
Tällöin ei tarvita esim. sitä wrapperi-koodia, eikä FFI:n infraa.
mavavilj kirjoitti:
Mutta FFI:tä käytelleenä olen sitä mieltä, että se, että monikielikoodista toteutetaan moduuleja on varmasti yksinkertaisempaa kuin FFI.
Nämähän ovat ratkaisemassa täysin eri ongelmaa, FFI on tarkoitettu valmiiden binäärimuodossa olevien vieraiden kirjastojen hödyntämiseen.
Esimerkiksi 8th:lla kirjoitin joskus minimaalisen tuen SDL2:n hyödyntämiseen ja sen render osassa oli:
ns: SDL "PPN4U" "SDL_CreateRenderer" func: CreateRenderer "NP" "SDL_RenderClear" func: RenderClear "VP" "SDL_RenderPresent" func: RenderPresent "NPPbb" "SDL_RenderCopy" func: RenderCopy "VP" "SDL_DestroyRenderer" func: DestroyRenderer "PPP" "SDL_CreateTextureFromSurface" func: CreateTextureFromSurface "VP" "SDL_DestroyTexture" func: DestroyTexture "NP1U1U1U1U" "SDL_SetRenderDrawColor" func: SetRenderDrawColor "NPb" "SDL_RenderFillRect" func: RenderFillRect \ Renderer flags 0x00000001 constant RENDERER_SOFTWARE 0x00000002 constant RENDERER_ACCELERATED 0x00000004 constant RENDERER_PRESENTVSYNC 0x00000008 constant RENDERER_TARGETTEXTURE
Kyllähän tuo helpompi on kertoa vaan kääntäjälle miten DLL tuontikirjastoja käsitellään kuin kirjoittaa koko kirjasto uusiksi toisella ohjelmointikielellä.
jalski kirjoitti:
(07.04.2024 13:31:54): ”– –” Nämähän ovat ratkaisemassa täysin eri...
Nojaa?
Tämä illustroimani multikieli antaisi kirjoittaa koodin lähdekoodin kielessä, eikä tarvitsisi wrapata lähdekoodia "hostikieleen". Tarvittaisiin vain tyyppikonversio.
mavavilj kirjoitti:
jalski kirjoitti:
(07.04.2024 13:31:54): ”– –” Nämähän ovat ratkaisemassa täysin eri...
Nojaa?
Tämä illustroimani multikieli antaisi kirjoittaa koodin lähdekoodin kielessä, eikä tarvitsisi wrapata lähdekoodia "hostikieleen". Tarvittaisiin vain tyyppikonversio.
Tässä tapauksessa olisi sitten ehkä parasta vain kirjoittaa kirjaston toiminnallisuus uusiksi yhdelle ohjelmointikielelle ja poistaa tarve useammalle ohjelmointikielelle.
jalski kirjoitti:
(07.04.2024 18:51:17): ”– –” Tässä tapauksessa olisi sitten ehkä parasta...
Niinhän voi tehdä muutenkin.
Ajattelin, että se olisi hedelmällistä vaan kyetä upottamaan lainattu koodi sen luontikielen idioomalla vieraskieliseen ohjelmaan, kuten C++ upottaa C:n. Näin voitaisiin kunnioittaa luontikieltä sellaisenaan ja hostikieliä sellaisenaan. Joskus wrappaaminen on sellainen "no ei me oikeasti haluttu tätä C:lle, joten wrapataanpa Java:lle".
Eikös tälle ole monessa kielessä tuki muutenkin? esim c# ja dllimport + extern:
[DllImport("CircleGPU2_32.DLL", EntryPoint = "Test",
CallingConvention = CallingConvention.StdCall)]
public static extern int Test();groovyb kirjoitti:
Eikös tälle ole monessa kielessä tuki muutenkin? esim c# ja dllimport + extern:
[DllImport("CircleGPU2_32.DLL", EntryPoint = "Test", CallingConvention = CallingConvention.StdCall)] public static extern int Test();
Jaaha, no C# nyt on muutenkin ollut parempi kuin Java tai Ruby, mutta C#:sta ei ole alustatuen takia hyötyä.
Tämä ei ole Fusion:in tai Haxe:nkaan nykytilanteeseen liittyvä idea.
Täytyy sanoa että mulle tulee tästä viestiketjusta väkisinkin fiilis, että keksitään ratkaisu ja sitten mietitään että mihin ongelmaan.
Kielestä toiseen vaihtaminen on lopulta pienimpiä murheita mitä ohjelmoinnin saralla vastaan tulee.
Proseduraalisesta ohjelmoinnista olio ohjelmointiin hyppääminen oli kloppina toki haaste, mutta siinäkään haaste ei johtunut kielestä vaan siitä että piti muuttaa ajattelutapaa.
Lähtökohtaisesti on vaan erittäin typerää vaihtaa jo toimivaa syntaksia toiseen. Sitä paitsi Fusion ja Haxe on kehitetty nimenomaan sen takia, ettei tarvitsisi kirjoittaa jokaista syntaksia erikseen, ja erityisesti Haxe:lla on vahva käyttäjäkunta.
Huomasin myös, että esimerkiksi Svelte:ssä käytetään hieman samanlaista # ja / syntaksia.
Tajusin tänään, että ideani mukailee hieman Go:n design goal:ia.
Go tiputtaa C:stä puolipisteet yms. turhaa syntaksia.
Åäö
Joka päivä oppii jotain uutta. Itse opin, että jauhenlihaa kannattaa ostaa pakkaseen jemmaan, kun ne ovat 1.99e/paketti tarjouksessa (tänään hinta oli 3.49e).
mpni kirjoitti:
Joka päivä oppii jotain uutta. Itse opin, että jauhenlihaa kannattaa ostaa pakkaseen jemmaan, kun ne ovat 1.99e/paketti tarjouksessa (tänään hinta oli 3.49e).
Seuraavaksi tulet oppimaan, ettei viimeisen käyttöpäivän lihan pakastaminen ja syöminen kuukautta myöhemmin ollutkaan hyvä idea.
Joskus tajusin että Bentsojen ja viinan sekoitus sopivassa suhteessa on loistava idea; se suhde osoittautui olevan 0/1.
muuskanuikku kirjoitti:
Seuraavaksi tulet oppimaan, ettei viimeisen käyttöpäivän lihan pakastaminen ja syöminen kuukautta myöhemmin ollutkaan hyvä idea.
Olipas sittenkin
muuskanuikku kirjoitti:
(28.06.2024 07:11:06): ”– –” Seuraavaksi tulet oppimaan, ettei viimeisen...
Kyllä täällä on lihat jemmattu ihan hirvenlihasta lähtien ja hyvin on maistunut, mutta nyt pois offtopic-aiheesta.
Kannattaa opetella Lisp- ja/tai Forth-sukuisia kieliä jos C-sukuisten kielten triviaalit syntaksierot ärsyttävät ja DSL:t kiinnostavat.
Esim. Racket mainostaa ihan etusivullaan tukea uusien kielten määrittelyyn. Ehkä mavaviljin idea on tätä parempi, mutta vaikea sanoa, kun github-repossa ei vielä ole paljoa sisältöä. Kannattaa pushata lokaalit muutokset silloin tällöin.
En ole lukenut tätä kirjaa, mutta sopisi varmasti mavaviljille: https://beautifulracket.com/ :D
Common Lispin makroillakin voi tehdä vaikka mitä, esim. lisätä kieleen Haskell-tyylisiä ominaisuuksia: Coalton. Mavaviljin mukaan hyvät koodarit kirjoittavat esimerkiksi "Haskell-tyyppistä C++:aa", joten ehkä tämäkin on hyvä idea.
Tätä ideaa on tosiaan monet muutkin käsitelleet, mutta erilailla.
Tuossa aika iso projekti:
https://github.com/luxe/unilang
joka on kuitenkin eri kuin:
https://bbs.deepin.org/en/post/243615
(referenssi: https://github.com/luxe/unilang/issues/468)
Perustelut ovat aika hyviä:
https://github.com/linuxdeepin/unilang?tab=readme-ov-file#the-origin
Näyttää tältä:
https://github.com/linuxdeepin/unilang/blob/
ja esim. uudelleenmääriteltävä def:
https://github.com/linuxdeepin/unilang/blob/
Koko dokumentointi:
Joo tiedän, että stack-kielet ovat parhaita, koska ne vastaavat lähiten tietokoneen operointia, mutta sen jälkeen kun luin, että ne eivät lopulta tuota juurikaan etua C:hen, niin lopetin niiden lukemisen.
Pitäisi vaan voida vaihtaa pieniä syntaktisia muotoiluja "on-demand". Ei vaihtaa itse kielen toteutusta, joka voi aina olla C ja C++. Oleellista on siis vain vaihtaa sitä, miltä se näyttää ohjelmoijalle kulloinkin.
Myös C++ tukee DSL:ien määrittelyjä: https://arne-mertz.de/2015/06/domain-specific-languages-in-c/
Lisp:ien opiskelu ei ole hedelmällistä, koska ne kuolivat jo kymmeniä vuosia sitten.
https://www.goodreads.com/quotes/226225-there-are-only-two-kinds-of-languages-the-ones-people
Ei ole sattumaa, että yllä Unilang on hyvin funktionaalinen.
Se ei kuitenkaan ollut sama idea kuin mitä esitin alussa. Minun ideani oli vain muokata jo käytetyt kielet sellaisiksi, että niitä voi käyttää yhdestä varioitavasta syntaksista. Sen takia, että on rasittavaa vaihtaa C++:sta Java:aan. Sen sijaan haluan kirjoittaa sitä, jota osaan paremmin tai joka on paremmin abstrahoitua, ja kääntää toiseen.
Esimerkiksi:
https://www.programiz.com/java-programming/examples/check-if-two-strings-are-anagram
Tulisi voida kirjoittaa:
import arrays; // tjsp
class Main { // luokka on vapaaehtoinen
void main(args) { // ei ole valia, mika argsien tarkka muoto on
string str1 = "Race"; // ei ole valia, tulisiko olla String vai std::string vai ...
// staattinen allokointi, koska ei new:ta
string str2 = "Care";
str1 = str1.toLowerCase(); // universaalin string-luokan metodi
str2 = str2.toLowerCase();
// check if length is same
if(str1.length() == str2.length()) { // string:eilla on aina length()
// convert strings to char array
char[] charArray1 = str1.toCharArray(); // string == char[]
char[] charArray2 = str2.toCharArray();
// sort the char array
charArray1.sort(); // kaytetaan char[] sort():ia kohdekielessa
charArray2.sort();
// if sorted char arrays are same
// then the string is anagram
bool result = (charArray1 == charArray2); // == on maaritelty kohdekielessa
if(result) {
print(str1 + " and " + str2 + " are anagram."); // ei ole valia, mika print:n tarkka syntaksi kohdekielessa on. Konkatenointi toimii, kuten oletetaan.
}
else {
print(str1 + " and " + str2 + " are not anagram.");
}
}
else {
print(str1 + " and " + str2 + " are not anagram.");
}
}
}Tästä pääsisi siten Python:iin tiputtamalla tyypit pois yms.
Mikäli haluaa kirjoittaa koodia mikä näyttää C++:lta, niin miksei vaan käyttäisi kyseistä ohjelmointikieltä? Ohjelmointikielestä toiseen vaihtaminen ei ole oikea ongelma mikä tarvitsisi ratkaista.
jalski kirjoitti:
Mikäli haluaa kirjoittaa koodia mikä näyttää C++:lta, niin miksei vaan käyttäisi kyseistä ohjelmointikieltä? Ohjelmointikielestä toiseen vaihtaminen ei ole oikea ongelma mikä tarvitsisi ratkaista.
"Some users may have concerns on the look and feel of the resulted "one" language. It is true that a unique and universal syntax can hardly work across different problem domains, because there are conflict needs on the syntax: we may need radically different visual styles for different purpose. But there is actually no law to rules out the possibility to support more than one sets of concrete syntaxes in one language.
So, the syntaxes of a language should not be the problem. If the syntax is not satisfying, just change it. This is done by users, but not the designers of the languages."
Enkä minä ainakaan muista Java:a ja C++:aa, jos en ole käyttänyt jompaa kumpaa viime aikoina. Pitää aina kerrata asioita. Jos pitää koodata siten, tetä katsoo samalla dokumentaatiosta syntaksia, niin tämä on merkki lähtökohtaisesti huonosta kielestä, koska sen semantiikka ei ole intuitiivinen.
Ehkä kannattaa vaan lukea https://github.com/linuxdeepin/unilang?tab=readme-ov-file#the-origin
Haluan itse siis, että C++:an voi halutessaan pudottaa Python:iksi ilman, että build chain muuttuu lainkaan.
Kielestä vaan näytetään versiota, jossa ei tarvitse välittää joistain asioista.
Minusta ongelma on hyvin relevantti Python:in ja C++:an kontekstissa, koska Python:istit haluaisivat enemmän staattisia ominaisuuksia ja nopeutta, C++:istit taas vähemmän syntaksia ja enemmän abstraktioita kuten range-for.
Unilang:in kontekstissa käyttäjälle pitäisi antaa myös paljon enemmän vapauksia vaihtaa syntaksia haluamaansa ilman, että kohdekieli muuttuu lainkaan. Unilang on toteutettu C++:lla tulkkina.
Itseasiassa minusta https://github.com/linuxdeepin/unilang/blob/
Tykkään ominaisuuksista kuten:
$remote-eval
make-environment
$access
myös
$set! self
on varsin elegantti.
Unilang ei siis muokkaa kohdekieliä, mutta se luo sellaisen välikielen, jolla voi käskyttää niitä muita.
Itse en vaan ymmärrä, miksi muka jonkun "joustavamman" ohjelmointikielen käyttäjä haluaisi mielummin kirjoittaa C/C++ tyylistä koodia?
Esimerkiksi tuo anagrammi esimerkkisi kirjoitettuna uusiksi vaikka 8th:lla:
private
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61,
67, 71, 73, 79, 83, 89, 97, 101 ] ( swap a:_@ ) curry: prime?
public
: prime-hash \ s -- s
s:lc 1 swap ( #p:prime? n:* ) s:each! "%x" s:strfmt ;
: app:main
["race", "care"] dup ' prime-hash a:group m:len nip 1 n:= if
"Words %s and %s are anagrams.\n"
else
"Words %s and %s are not anagrams.\n"
then s:strfmt . ;jalski kirjoitti:
(01.01.2025 13:21:17): Itse en vaan ymmärrä, miksi muka jonkun...
Jospa vaan luet sen tekstin siellä Unilang:in repossa, siinä kerrotaan. Unilang vastaa ongelmaan, jossa eri kielissä on hyödyllisiä ominaisuuksia, mutta myös puutteita. Tällöin on paras käyttää kieltä, joka käyttää muita kieliä.
Unilang ei ole C/C++, mutta koska suurin osa hyödyllisestä koodista on C/C++:lla, niin se muodostaa Unilang:iinkin merkittävän kohdekielen. Täällä https://medium.com/@deepinlinux/unilang-the-new-programming-language-independently-developed-by-deepin-a442f6fcc0ad sivutaan myös Racket:ia. Unilang:issa näyttäisi siis olevan valtavasti näkemystä.
Voisi kyllä katsoa myös 8th:iä tähän ongelmaani. Edit: paitsi en ollutkaan tajunnut, että se on kaupallinen.
Tosiaan, eilen ajattelin, että mitä tehdä, jos joissain projekteissa skriptikieli on Python ja joissain JavaScript.
Sitten ajattelin, että mitä jos käyttäisi staattista analysaattoria siten, että voisi kirjoittaa JavaScript:iä esim. Python:ia odottavaan tulkkiin ilman, että varsinaisesti syöttää sille JavaScript:iä.
Eli jos voisi kirjoittaa JavaScript:iä ja sitten tällaisella analysaattorilla vaan vähän muokkaa, jotta siitä tulee validia Python:ia.
Minusta Python ei tuota kuitenkaan JS:iin mitään, joten pitäisi onnistua. Python on myös niin väärin käytetty kieli, että olisi parempi kirjoittaa Python-JS:iä.
Tämä oli mielenkiintoinen:
https://codingfleet.com/code-converter/javascript/python/
mutta ehkä jopa enemmän kuin tarvitaan.
Lisäksi olisi kiva tietää, että voiko tuollainen kääntäjä olla 100% oikein.
jalski kirjoitti:
Suurimman osan ohjelmointikielten syntakseista oppii viikonlopussa sille tasolle, että pystyy sillä työskentelemään.
Ai niin ja olennaista ei ole vain syntaksi, vaan myös kääntäjä ja runtime.
Eli että muistaa, miten ohjelmat aloitetaan eri kielissä ja miten niiden namespace:t yms. tuotetaan.
Esimerkiksi C++:ssa pitää muistaa vaikkapa rule of three, mutta sitä ei tarvitsisi muistaa Python:issa. Entä jos kirjoitat molempia?
Ko. analysaattorin tulisi siis sisältää myös objektien elinkaarien näkyvyys tai sisältää se sellaisella tasolla, jossa esim. C++:ssa on automaattisesti käytössä smart pointer:it, jos toinen kieli on GC/dynaaminen.
Mutta esimerkiksi:
https://www.codeconvert.ai/python-to-c -converter
on niin hyvä jo pienillä esimerkeillä, että ei ole kauheasti etua kirjoittaa C++:n syntaksia suoraan.
Ajattelin tässä tänään, että miksi tässä ei ole samankaltaisuuksia esim. Cython:iin:
https://cython.readthedocs.io/en/latest/src/
Mutta Cython:in tapa tehdä tämä vasta onkin ruma:
Ensin kirjoitetaan:
i: cython.int
Sitten saadaan:
cdef int i
Miksi ei kirjoiteta samantien cdef int i?
Miksi kirjoitetaan cdef int i eikä int i? Jos int sekoittuu johonkin, niin miksi ei sitten cint?
---
Tässä yksi esimerkki, millaista on kirjoittaa kaikkia kieliä:
https://github.com/Yuvix25/Pytov
---
Oleellista on edelleen, että emme siis halua puuttua runtimeen ja kääntäjiin lainkaan, mutta haluaisimme näyttää ohjelmakoodista piirteitä muista kielistä, jotta ohjelman tulkitseminen olisi "monikielisempää" ja jotta siinä voisi kehitysvaiheessa käyttää ohjelmoijalle selkeimpiä abstraktioita, mutta puuttumatta kääntäjään.
Cython:in tapauksessa haluaisimme tosiasiassa, että koodi on edelleen C:tä, mutta se vain näyttää erilaiselta.
Aion demota tätä ideaa kuitenkin, joten jos joku on kiinnostunut, niin voi liittyä.
Ratkaisu on kuitenkin luultavasti GPL, joten mitään kaupallisuutta asiaan ei liity.
Ensimmäinen ideani on tyypittämätön ja "roskienkerätyltä näyttävä" C.
Voitte laittaa tänne esimerkki-koodeja, joihin haluatte "pythonisoinnin".
Esimerkki:
FILE *input = fopen("input.txt", "r");=
input = open('input.txt', 'r')Mitä analysaattori tekee:
-piilota tyyppi, koska se voidaan päätellä (std) open-funktiosta
-pointer == alias object
-fopen == alias open
-' == alias "
-; on optional
Analysaattori hyväksyy simple-moodissa aliaksissa kaikki variantit, joten yo. voitaisiin kirjoittaa myös esim.:
input = fopen("input.txt", "r");ja kyse on vain siitä, että preferoiko kirjoittaja C:n standardikirjastoa ja ;-merkkiä vai enemmän Pythonia. Koodi tietysti lopulta tekee sen, mitä fopen tekee.
Mutta tässä esiteltiin jo objekti, joten jatkossa simple-moodissa haluaisi myös tehdä:
input.read(CHAR_BIT)
eikä fgetc(input).
Tässä pitäisi siis tunnistaa, että obj.read(CHAR_BIT) on sama kuin fgetc(obj). Koska kyseessä on alias, niin voisi myös kirjoittaa fgetc(input). Meidän ei tarvitse välittää siitä, että onko obj validi, se on ohjelmoijan tehtävä varmistaa se.
Erityisesti myös, simple-moodissa ei pitäisi joutua välittämään siitä, että onko kyseessä
input.read(CHAR_BIT) vai input->read(CHAR_BIT) // tämä vain eksplikoi, että obj on * vai read(input, CHAR_BIT) // C-tyylinen variantti
ja jo nyt simple-moodi on ekspressiivisempi kuin C tai Python kumpikaan.
Onks sulla nyt siis joku ohjelma joka tuota muunnosta tekee vai onko vaan suunnitelma?
wy5vn kirjoitti:
Onks sulla nyt siis joku ohjelma joka tuota muunnosta tekee vai onko vaan suunnitelma?
Tässä ketjussa on suunniteltu, mutta nyt aion alkaa tekemään sitä, koska olen 95% varma, että sille on tarvetta, koska mikään ketjussa käsitelty muu "unilang" ei oikein toteuta tätä ideaa ja minusta tämä on yksinkertaisuuden takia parempi kuin unilangit, erityisesti rajalliseen "haluan pythonic C/C++:n" -ongelmaan.
High-level idea on siis:
- Kaikki koodi on C/C++:aa (myöhemmin ehkä myös Rust:ia)
- Koska analysaattorilla on alias-assosiaatioita ja vastaavia, niin C/C++:aa voi kirjoittaa ja lukea Pythonistisesti ilman C/C++:n visuaalisesti sotkevia ominaisuuksia, jotka analysaattori tietää
- Analysaattorissa on esim. alkuun yksi nappi kahdella moodilla: "source" ja "simple" (eli "pythonisointi"). "Source" näyttää C/C++ -lähdekoodin, jota käsitellään, ja "simple" näyttää siitä version, joka muistuttaa enemmän Pythonia. Molempia kieliä voi kirjoittaa ja muokata, kunhan muokkaukset tehdään oikeassa osiossa. Analysaattori osaa täydentää C/C++:ksi "simple"-koodia (kunhan se on analysaattorin odottaman mukaista eli syntaksi sisältää riittävät vihjeet) ja vice versa
- Koodi käännetään vain C/C++ -kääntäjällä, "simple"-koodi ei ole sinällään käännettävää, vaan ainoastaan "näkymä koodista"
- Analysaattori ei tarvitse mitään uusia tulkkeja, kääntäjiä tai FFI:ja tms. Se on standardia C/C++:aa ja tekstimuokkausta. Toisin kuin esim. Cython, niin analysaattori ei vaadi uuden välikielinotaation (cdef etc.) käyttämistä.
Kun "simple" toimii Pythonimaiseksi, niin voi miettiä, miten siitä saadaan pseudo-Java ja pseudo-JavaScript myös. Lopulta ehkä myös, miten voidaan esittää C++ funktionaalisena koodina tms.
Unilangit ovat hyödyllisiä, jos pitää deployata useisiin eri runtimeihin yhdestä koodibasesta, mutta se ei ratkaise analysaattorin ratkaisemaa ongelmaa, joka on vain, että suurelle osalle käyttäjistä Pythonin tärkein puoli on produktiivisuus ja koodin luettavuus, jota C/C++ taas ei anna. Vastaavasti Pythonin huono puoli on nopeus ja rajoittuneisuus, jonka taas C/C++ korjaa.
Huomioitavaa on, että C++:n lisäämät Pythonimaiset ominaisuudet, kuten range-based for loop osoittavat jo, että C++:n pythonisoiminen on vain sitä, että "näytetään sama asia eri syntaksilla".
Ajattelin kokeilla alkuun, että voiko tätä demota LibreOffice Calc:in makroilla.
Koodi lokeroihin siten kuin se tokenisoitaisiin.
Sitten makrolla piilottaa ne, mitä ei tule simple-moodiin.
Parseri voi olla epätriviaali, ellei ensin suunnittele, mitä kannattaa muokata simple-moodiin.
Lisäksi, jos sille löytyy hyvä parseri sinänsä, niin simple-moodin voi tehdä vain muokkaamalla sen puuta. Täällä https://blog.trailofbits.com/2022/12/22/syntax-searching-c-c-clang-ast/ tosin sanotaan, että parserointi olisi itsessään vaikea ongelma, joten mahdollisesti tämä analysaattori pitää lopulta tehdä sellaiseksi, että se ymmärtää vain yhden rivin kerrallaan, ei konteksteja tms. Lisäksi sillä on oma taulukko asioista, jotka liittyvät toisiinsa, kuten aliakset. Eräs mahdollisuus on, että koodatessa projektia analysaattorille opetetaan oman koodin piirteet, kuten mitä funktioita on olemassa ja mitkä aliakset niille sallitaan. Jatkossa samaa ei sitten tarvitse enää kertoa uudestaan, vaan se tietää jatkossa, että open == fopen ja näiden LHS on aina File *. " == ' taas voidaan päätellä rivikohtaisesti.
Libclangissa on tokenizer, joten olisi näppärää sitoa tämä analysaattori siihen:
https://clang.llvm.org/docs/LibClang.html
https://eli.thegreenplace.net/2011/07/03/parsing-c-in-python-with-clang
Translaattori voisi myös leipoa sisään syntaksit tästä projektista, jota tietääkseni juuri kukaan ei käytä:
Hieno idea oli, mutta eipä oikeen korvaa C++:aa. Tekee kylläkin C:stä helpomman.
https://www.libcello.org/learn/cello-vs-cpp-vs-objc
"The high level structure of Cello projects is inspired by Haskell, while the syntax and semantics are inspired by Python and Objective-C."
Translaattorin idea on kuitenkin, ettei tarvitsisi bindata C API:en tai tehdä sellaista, vaan ainoastaan muokata C/C++ -syntaksia mieluisaksi näkymäksi ja/tai hyväksyä siihen mieluisan syntaksin, mutta koodi on silti lopulta C/C++:aa.
Saisiko esim. vasemmanpuoleisesta enemmän oikean näköistä lisäämällä tai poistamalla syntaksia?
Vasemmallahan tehdään melkein sama komputaatio, mutta C++:n omat tyylit, kuten
typedef
vaan tekevät koodista hankalampaa lukea. Lisäksi on esim. typerää joutua toistamaan asioita, kuten:
intmap<list<K>>
vaikka templaten perusteella input-tyyppi tiedetään jo.
---
Huom.
clang:issa on itsessään vielä ominaisuus:
clang -Xclang -ast-dump test.cpp
https://clang.llvm.org/docs/
Tämä on ehkä helpoin työkalu, koska tällöin ei tarvitse muutakuin parserin tuon outputille. HUOM: tuo tulostaa myös kaikkien #includien tiedot, joiden poistamiseksi ei ole toistaiseksi löytynyt keinoa.
Lisäksi:
"Clang’s AST is different from ASTs produced by some other compilers in that it closely resembles both the written C++ code and the C++ standard."
joten tämä on ehkä turvallinen, jotta C++:n kaikkiin piirteisiin pääsee käsiksi.
Siitä hieman hienompi formatointi:
https://stackoverflow.com/a/57981374
tai JSON-formatointi:
clang -Xclang -ast-dump=json test.cpp
Lisäksi vaikka clang-check https://stackoverflow.com/a/28217572
Voi olla avuksi:
https://llvm.org/devmtg/2013-04/klimek-slides.pdf
---
Yllämainittu cppast on "deprecated":
https://github.com/standardese/cppast/issues/173
koska clangin ast-dump tekee saman asian.
Esimerkkikoodi -ast-dumpille esim.:
// Program to illustrate the working of
// objects and class in C++ Programming
#include <iostream>
using namespace std;
// create a class
class Room {
public:
double length;
double breadth;
double height;
double calculate_area() {
return length * breadth;
}
double calculate_volume() {
return length * breadth * height;
}
};
int main() {
// create object of Room class
Room room1;
// assign values to data members
room1.length = 42.5;
room1.breadth = 30.8;
room1.height = 19.2;
// calculate and display the area and volume of the room
cout << "Area of Room = " << room1.calculate_area() << endl;
cout << "Volume of Room = " << room1.calculate_volume() << endl;
return 0;
}https://www.programiz.com/cpp-programming/object-class
---
Nyt ongelmana on lähinnä, että kuinka helppoa on tietää, miten tietää C++-koodimuutokset, jos tekee muutoksia simple-moodissa ts. "redusoidussa AST:ssa", jossa myös asiat muuttuivat.
Ehkä pitäisi kasata ensin se redusoitu AST.
Tällä tulee Pythonin clang-bindeillä siistimpää tulostetta:
import sys
import clang.cindex
def print_all(cursor, i):
print('\t' * i, cursor.kind, ':', cursor.spelling, '(', cursor.location, ')')
for child in cursor.get_children():
print_all(child, i+1)
if __name__=='__main__':
tu = clang.cindex.Index.create().parse(sys.argv[1])
print_all(tu.cursor, 0)Credits: https://stackoverflow.com/q/66023924
Esim. yo. Room-tiedostolle ilman #includea:
python3 parser.py testcpp.cpp
CursorKind.TRANSLATION_UNIT : testcpp.cpp ( <SourceLocation file None, line 0, column 0> )
CursorKind.USING_DIRECTIVE : ( <SourceLocation file 'testcpp.cpp', line 4, column 17> )
CursorKind.NAMESPACE_REF : std ( <SourceLocation file 'testcpp.cpp', line 4, column 17> )
CursorKind.CLASS_DECL : Room ( <SourceLocation file 'testcpp.cpp', line 7, column 7> )
CursorKind.CXX_ACCESS_SPEC_DECL : ( <SourceLocation file 'testcpp.cpp', line 9, column 4> )
CursorKind.FIELD_DECL : length ( <SourceLocation file 'testcpp.cpp', line 10, column 12> )
CursorKind.FIELD_DECL : breadth ( <SourceLocation file 'testcpp.cpp', line 11, column 12> )
CursorKind.FIELD_DECL : height ( <SourceLocation file 'testcpp.cpp', line 12, column 12> )
CursorKind.CXX_METHOD : calculate_area ( <SourceLocation file 'testcpp.cpp', line 14, column 12> )
CursorKind.COMPOUND_STMT : ( <SourceLocation file 'testcpp.cpp', line 14, column 29> )
CursorKind.RETURN_STMT : ( <SourceLocation file 'testcpp.cpp', line 15, column 9> )
CursorKind.BINARY_OPERATOR : ( <SourceLocation file 'testcpp.cpp', line 15, column 16> )
CursorKind.UNEXPOSED_EXPR : length ( <SourceLocation file 'testcpp.cpp', line 15, column 16> )
CursorKind.MEMBER_REF_EXPR : length ( <SourceLocation file 'testcpp.cpp', line 15, column 16> )
CursorKind.UNEXPOSED_EXPR : breadth ( <SourceLocation file 'testcpp.cpp', line 15, column 25> )
CursorKind.MEMBER_REF_EXPR : breadth ( <SourceLocation file 'testcpp.cpp', line 15, column 25> )
CursorKind.CXX_METHOD : calculate_volume ( <SourceLocation file 'testcpp.cpp', line 18, column 12> )
CursorKind.COMPOUND_STMT : ( <SourceLocation file 'testcpp.cpp', line 18, column 31> )
CursorKind.RETURN_STMT : ( <SourceLocation file 'testcpp.cpp', line 19, column 9> )
CursorKind.BINARY_OPERATOR : ( <SourceLocation file 'testcpp.cpp', line 19, column 16> )
CursorKind.BINARY_OPERATOR : ( <SourceLocation file 'testcpp.cpp', line 19, column 16> )
CursorKind.UNEXPOSED_EXPR : length ( <SourceLocation file 'testcpp.cpp', line 19, column 16> )
CursorKind.MEMBER_REF_EXPR : length ( <SourceLocation file 'testcpp.cpp', line 19, column 16> )
CursorKind.UNEXPOSED_EXPR : breadth ( <SourceLocation file 'testcpp.cpp', line 19, column 25> )
CursorKind.MEMBER_REF_EXPR : breadth ( <SourceLocation file 'testcpp.cpp', line 19, column 25> )
CursorKind.UNEXPOSED_EXPR : height ( <SourceLocation file 'testcpp.cpp', line 19, column 35> )
CursorKind.MEMBER_REF_EXPR : height ( <SourceLocation file 'testcpp.cpp', line 19, column 35> )
CursorKind.FUNCTION_DECL : main ( <SourceLocation file 'testcpp.cpp', line 23, column 5> )
CursorKind.COMPOUND_STMT : ( <SourceLocation file 'testcpp.cpp', line 23, column 12> )
CursorKind.DECL_STMT : ( <SourceLocation file 'testcpp.cpp', line 26, column 5> )
CursorKind.VAR_DECL : room1 ( <SourceLocation file 'testcpp.cpp', line 26, column 10> )
CursorKind.TYPE_REF : class Room ( <SourceLocation file 'testcpp.cpp', line 26, column 5> )
CursorKind.CALL_EXPR : Room ( <SourceLocation file 'testcpp.cpp', line 26, column 10> )
CursorKind.BINARY_OPERATOR : ( <SourceLocation file 'testcpp.cpp', line 29, column 5> )
CursorKind.MEMBER_REF_EXPR : length ( <SourceLocation file 'testcpp.cpp', line 29, column 11> )
CursorKind.DECL_REF_EXPR : room1 ( <SourceLocation file 'testcpp.cpp', line 29, column 5> )
CursorKind.FLOATING_LITERAL : ( <SourceLocation file 'testcpp.cpp', line 29, column 20> )
CursorKind.BINARY_OPERATOR : ( <SourceLocation file 'testcpp.cpp', line 30, column 5> )
CursorKind.MEMBER_REF_EXPR : breadth ( <SourceLocation file 'testcpp.cpp', line 30, column 11> )
CursorKind.DECL_REF_EXPR : room1 ( <SourceLocation file 'testcpp.cpp', line 30, column 5> )
CursorKind.FLOATING_LITERAL : ( <SourceLocation file 'testcpp.cpp', line 30, column 21> )
CursorKind.BINARY_OPERATOR : ( <SourceLocation file 'testcpp.cpp', line 31, column 5> )
CursorKind.MEMBER_REF_EXPR : height ( <SourceLocation file 'testcpp.cpp', line 31, column 11> )
CursorKind.DECL_REF_EXPR : room1 ( <SourceLocation file 'testcpp.cpp', line 31, column 5> )
CursorKind.FLOATING_LITERAL : ( <SourceLocation file 'testcpp.cpp', line 31, column 20> )
CursorKind.RETURN_STMT : ( <SourceLocation file 'testcpp.cpp', line 37, column 5> )
CursorKind.INTEGER_LITERAL : ( <SourceLocation file 'testcpp.cpp', line 37, column 12> )Nopeus voi olla tsägällä riittävä Pythonillakin, erit. jos käsitellään vain näkyvää koodia, eikä koko tiedostoa.
Tervetuloa:
The Unified Programming Language Interpolator
https://github.com/mavavilj/UPLI/
Tässä siis projektin aloitus.
Lisenssi on LGPL-3.0-or-later, jotta ohjelmaa voi käyttää kirjastona mihin lisenssiin vain, mutta ohjelmaan itseensä tehdyt lisäykset tulee julkaista.
Tekstit ajattelin laittaa https://www.gnu.org/licenses/fdl-1.3.html
Sitä mä oon kyllä aina välillä vähän miettinyt että mihin noita lisenssejä tarvii. Miksi ei voi vaan sanoa et saa käyttää ja sillä siisti.
wy5vn kirjoitti:
Sitä mä oon kyllä aina välillä vähän miettinyt että mihin noita lisenssejä tarvii. Miksi ei voi vaan sanoa et saa käyttää ja sillä siisti.
Koska se ei ole välttämättä lakiteknisesti pitävää.
Mietin myös etukäteen, että on mahdollista, että projekti on joskus kiinnostava jollekin kaupalliselle käyttäjälle ja siinä vaiheessa on hyvä, jos se ei voi varastaa sitä tuosta vain. Esimerkki, olisi harvinaisen ikävää, jos kirjoittaisit avoimena lähdekoodina jonkin tekoälybotin ja sitten joku yritys katsoisi, että jaaha otetaanpa ja tehdään vähän muutoksia ja sitten julkaistaan se AutoBot -tuotteena hintaan $299 lisenssi.
GPL on hyödyllinen siinä mielessä, että sen mukaan jokaisen käyttäjän on pakko julkaista tekemänsä muutokset, eikä se voi pitää niitä itsellään. Näin ollen kirjaston käyttäjä maksaa veroa käyttöoikeudesta siten, että tehdyt parannukset pitää myös antaa takaisin muiden käyttöön. Permissive-lisenssillä joku voi ottaa koodit ja tehdä niihin muutoksia ja jatkaa tämän jälkeen kirjaston kehitystä suljettuna. Tällöin koodia käytetään lähinnä vain ilmaislounaana antamatta mitään itse takaisin.
wy5vn kirjoitti:
Miksi ei voi vaan sanoa et saa käyttää ja sillä siisti.
WTFPL voisi sopia sulle.
mavavilj kirjoitti:
GPL on hyödyllinen siinä mielessä, että sen mukaan jokaisen käyttäjän on pakko julkaista tekemänsä muutokset, eikä se voi pitää niitä itsellään.
Mistä kohtaa GPL:ää tämä käyttäjiin kohdistuva pakotus löytyy?
jlaire kirjoitti:
(16.02.2025 17:50:42): ”– –” WTFPL voisi sopia sulle. ”– –” Mistä...
https://www.tldrlegal.com/license/gnu-general-public-license-v3-gpl-3
"Any modifications to or software including (via compiler) GPL-licensed code must also be made available under the GPL along with build & install instructions."
GPL-poppoiden mielestä ko. vaade on välttämätöntä, jotta estetään ilmaisohjelmien kontribuutioiden valuminen korporaatioiden käsiin vailla vastavuoroisuutta.
Toki joku spekuloi, että mitä jos ei kerro, että käytti kirjastoa. Tämä kuitenkin selviää, sillä kirjasto pitäisi käytännössä prosessoida tunnistuskelvottomaksi. Tällöin tätä myös nimitetään GPL-violationiksi:
https://www.gpl-violations.org/
Vahvempi käytäntö on kerätä lataajista tunnistetietoa, jolloin on teoriassa mahdollista liittää väärinkäytös ja jonkun henkilötiedot tms.
Tällä jo melko luettava clang.cindex AST pohjautuen yo. koodiin:
import sys
import clang.cindex
def print_all(cursor, i):
print('\t' * i, cursor.displayname, ':', cursor.type.spelling)
for child in cursor.get_children():
print_all(child, i+1)
if __name__=='__main__':
tu = clang.cindex.Index.create().parse(sys.argv[1])
print_all(tu.cursor, 0)#include:t vaan tuottaa hirveästi jotain standardikirjaston dependency-tulosteita. Varsinainen ohjelmakoodi on vain pieni osa koko tulosteen pohjalla. #include on kuitenkin oltava, koska muuten parseri ei näe #includeissa olevia asioita, kuten cout:ia.
Myös tästä tulee ihan hieno JSON. Tässä suodatetaan ne alun include-roskat yms. pois:
import sys
import subprocess
import json
def filter_ast_only_source_file(source_file, json_ast):
new_inner = []
first_occurrence_of_main_file = False
for entry in json_ast['inner']:
if not first_occurrence_of_main_file:
if entry.get('isImplicit', False):
continue
file_name = None
loc = entry.get('loc', {})
if 'file' in loc:
file_name = loc['file']
if 'expansionLoc' in loc:
if 'file' in loc['expansionLoc']:
file_name = loc['expansionLoc']['file']
if file_name != source_file:
continue
new_inner.append(entry)
first_occurrence_of_main_file = True
else:
new_inner.append(entry)
json_ast['inner'] = new_inner
source_file = sys.argv[1]
generated_ast = subprocess.run(["clang", "-Xclang", "-ast-dump=json", source_file], capture_output=True) # Output is in bytes. In case it's needed, decode it to get string
# Parse the output into a JSON object
json_ast = json.loads(generated_ast.stdout)
filter_ast_only_source_file(source_file, json_ast)
print(json_ast)Credits: https://stackoverflow.com/a/71128654
Tokeniparserointi voi olla joskus hyödyllistä:
import sys
import clang.cindex
def srcrangestr(x):
return '%s:%d:%d - %s:%d:%d' % (x.start.file, x.start.line, x.start.column, x.end.file, x.end.line, x.end.column)
def main():
index = clang.cindex.Index.create()
tu = index.parse(sys.argv[1], args=['-x', 'c++'])
for x in tu.cursor.get_tokens():
print(x.kind)
print(" " + srcrangestr(x.extent))
print(" '" + str(x.spelling) + "'")
if __name__ == '__main__':
main()Tällä näkyy kommentit yms.
Credits: https://stackoverflow.com/a/19200713
https://clang.llvm.org/extra/pp-trace.html
saattaa antaa preprocessorin asioista lisää tietoa.
Tarvitaan parempi testi.cpp, koska aiemmassa ainoa merkittävä muutos on:
// calculate and display the area and volume of the room
print("Area of Room = ", room1.calculate_area())
print("Volume of Room = ", room1.calculate_volume());Hyvä työkalu Clang-AST:n lukemiseen:
Miksi ei vaan käytä valmista tapaa?
groovyb kirjoitti:
Miksi ei vaan käytä valmista tapaa?
No, koska se on Pythonin runtimen takia > 10x hitaampi (tai jopa 100x hitaampi https://www.mdpi.com/electronics/electronics-12-00143/article_deploy/html/images/electronics-12-00143-g008.png) ja koska bindien kirjoittaminen on tuskaa, koska juuri mikään FFI ei tosiasiassa tue kaikkia C++:n konstruktioita ja koska se vaatii toisen kielen idioomiin tarttumista. Lisäksi bindaaminen vaatii API:n muodostamista, joten se ei ole sama asia kuin DSL. Noissa bindeissä ei ole juuri mitään etua verrattuna tähän UPLI:n paradigmaan. Ehkä joku pitää etuna parempia kääntäjäviestejä. Python on syntaktisesti hyvä kieli, mutta runtime on lähinnä vain demo.
Pitäisi kysyä, miksi joku tekee erillisen runtimen ja huonon tulkin sen sijaan, että muokkaisi vain C/C++:aa nätimmäksi zero-cost tai tekisi edes https://nim-lang.org/
Onko tämä muka yksinkertaisempaa?
https://pybind11.readthedocs.io/en/stable/
Sitten myös:
Some reasons to avoid Cython
https://pythonspeed.com/articles/cython-limitations/
jossa erityisesti:
"On the other hand, if you expect you’ll be writing extensive amounts of new code, you’ll want something better. My suggestion: Rust." eli ei edes suositella Pythonia.
Luulen, että Stroustrup pitäisi enemmän tästä UPLI:n versiosta.
Sitä paitsi se sanoo itse, että:
"First of all, nobody should call themselves a professional if they only knew one language. And five is a good number for languages to know reasonably well."
"Let’s see, C++, of course; Java; maybe Python for mainline work... And if you know those, you can’t help know sort of a little bit about Ruby and JavaScript, you can’t help knowing C because that’s what fills out the domain and of course C-Sharp. But again, these languages create a cluster so that if you knew either five of the ones that I said, you would actually know the others."
https://bigthink.com/videos/big-think-interview-with-bjarne-stroustrup/
UPLI:n tarkoitus ei ole realisoida vain Python-C++ -interpolaatiota, vaan myös Java-C++, Haskell-C++, PL/I-C++ jne., jotta voidaan käyttää C/C++ -kirjastoja, mutta paremmalla käytettävyydellä ja vähemmällä purismilla. Idea on, että halutessaan syntaksin voi myös täysin kustomoida.
Onhan kuitenkin totta, että esim.
if __name__=='__main__':
on käytännössä sama asia kuin main().
Tässäkin yksi idea:
https://www.reddit.com/r/ProgrammerHumor/
Tosiaan, jotkin asiat ovat paljon helpompia kuin AST-analysointi:
#include <iostream>
using namespace std;
#define start int main()
#define print(a,b,sep) cout<<a<<sep<<b<<endl;
#define end return 0;
// MicroCython++
start {
print("jonne","petter",",")
end
}Niin, taisit vaan missata pointin. Joskus on tarve käyttää esim. laitevalmistajan kirjastoja. Ja jokaisen käytetyn kirjaston ei tietystikään tarvitse olla tehty samalla kielellä, millä itse tekee ohjelmistoa. Siksi ne on kirjastoja.
groovyb kirjoitti:
Niin, taisit vaan missata pointin. Joskus on tarve käyttää esim. laitevalmistajan kirjastoja. Ja jokaisen käytetyn kirjaston ei tietystikään tarvitse olla tehty samalla kielellä, millä itse tekee ohjelmistoa. Siksi ne on kirjastoja.
Joo toki kirjastoja voi käyttää eri kielistä, mutta siinä, että käyttökieli on sama kuin kirjaston kieli on selviä etuja.
Sitä paitsi MicroCython++ yllä saavuttaa jo luultavasti monille Python:ista tutut edut. Itseasiassa tuo on parempaa kuin Python, koska siinä ei ole myöskään jotain verbosea main-lausetta tai tietokonemaista return-lausetta.
Tuosta vaikka lisää Python-print:iä:
https://dev.to/philip82148/i-made-a-c-version-of-consolelog-o88
Point being: Python on siedettävä syntaksissa, ei runtimessa. Java on siedettävä VM:nä, ei syntaksissa eikä GC:ssa. C++ on siedettävä suorituskyvyssä ja joustavuudessa, ei RAD:issa. Haskell on siedettävä turvallisuudessa ja luettavuudessa, ei kirjastojen määrässä. ...
Tuosta vähän Haskellia:
Niin, jos kerran on tarve kirjoittaa C++:aa, miksi ei vaan sitten kirjoita C++:aa eikä säädä jollain MicroCythonilla tai ironpythonilla jne yms. Enemmän vaan tulee ongemia kun rupee soppaan sotkemaan erilaisia asioita
groovyb kirjoitti:
Niin, jos kerran on tarve kirjoittaa C++:aa, miksi ei vaan sitten kirjoita C++:aa eikä säädä jollain MicroCythonilla tai ironpythonilla jne yms. Enemmän vaan tulee ongemia kun rupee soppaan sotkemaan erilaisia asioita
https://en.wikipedia.org/wiki/
Tykkään MicroCython++:ista ja aion tehdä sitä lisää.
mavavilj kirjoitti:
Tykkään MicroCython++:ista ja aion tehdä sitä lisää.
Tuon kaltainen esikääntäjällä merkkijonojen korvaaminen ei varmasti paranna kenenkään tuottavuutta. Virhetilanteessa debuggaaminen ja kääntäjän viestien tulkkaus ei varmasti tule olemaan kovinkaan kivaa...
jalski kirjoitti:
(19.02.2025 15:33:14): ”– –” Tuon kaltainen esikääntäjällä...
Demonstroi.
Tässä on sekin puoli, että helpommalla kielellä ohjelmoija ei välttämättä tee niin paljoa virheitä, koska syntaksi on helpompi lukea. Siten voi olla, että pelkkä rivinumeron antaminen riittää selvittämään bugin.
”helpommalla kielellä”. Ei se C++ mitään taikuutta ole, mikset vaan opettelisi sitä sen sijaan että yrität oikeuttaa tuollaisten viritysten käytön, jotka ei tuo yhtään mitään lisäarvoa.
groovyb kirjoitti:
”helpommalla kielellä”. Ei se C++ mitään taikuutta ole, mikset vaan opettelisi sitä sen sijaan että yrität oikeuttaa tuollaisten viritysten käytön, jotka ei tuo yhtään mitään lisäarvoa.
Ei vaan C++ ei tuo nykymaailmassa lisäarvoa, koska sama ongelma voidaan ratkaista usein Python:illa vaikka se olisi 30x hitaampi.
C++ on huomattavasti vähemmän produktiivinen kuin helpompi kieli johtuen siitä, että syntaksia on paljon. Yleensäkään sitä ei tulisi edes valita ensimmäiseksi toteutuskieleksi, jos tämä on premature optimization. Sen sijaan, jos C++:ssa voidaan saavuttaa myös nopea RAD, niin tämä on parempi kuin muut.
Eli reddit-meemien avulla saadaan C++:aan parempi tuki jollekin viime vuosituhannen ohjelmointikehityksen mallille? Ihan huikeaa.
mavavilj kirjoitti:
Demonstroi.
Tässä on sekin puoli, että helpommalla kielellä ohjelmoija ei välttämättä tee niin paljoa virheitä, koska syntaksi on helpompi lukea. Siten voi olla, että pelkkä rivinumeron antaminen riittää selvittämään bugin.
Luuletko, että C-kääntäjän antaman virheen rivinumero täsmää koodin kanssa minkä esikääntäjä on muokannut? Lisäksi virheet ovat C-kääntäjän antamia C-kielen virheitä ja ne voivat olla samasta syystä vaikeita paikantaa.
Ohjelmointityökalulla pitää olla mahdollisuus debugata ja tutkia kääntäjän tuottamaa koodia. Venäläisetkin ovat vanhan DR-PL1 kääntäjän pohjalta tehneet oman kääntäjän mikä nykypäivänä tuottaa 64-bittistä koodia toisinkin vanha esikuvansa. Debuggeri on suoraan mukana käännetyssä tiedostossa.
C:\temp>testi ?? çáúÓÒº¬á õᮽá ßßÙ½«¬ #256 AX=0000 BX=020D CX=0063 DX=0000 SP=0014 BP=0000 SI=0043 DI=0041 0054 0014 88A0 0000 FF18 0000 7200 AB06 R8=0000 R9=0000 R10=0000 R11=0000 R12=0000 R13=0000 R14=0000 R15=0000 CTÉ 0056 0056 0004 0246 0000 0000 0000 0000 CS=0033 DS=002B SS=002B ES=002B FS=0053 GS=002B IP=0040120A --I------ 0040120A 6A00 PUSH 00000000 -g .testi_wndproc AX=0042 BX=0014 CX=0040 DX=0000 SP=0014 BP=0040 SI=0041 DI=020F E400 F5C0 5033 0010 F5D8 4FD8 ADED 9E59 R8=0014 R9=0014 R10=0000 R11=0000 R12=0000 R13=0014 R14=0000 R15=0000 CTÉ F4C8 F580 0000 0246 0000 F8E0 0024 0000 CS=0033 DS=002B SS=002B ES=002B FS=0053 GS=002B IP=004012DF --I-S-APC 004012DF .TESTI_WNDPROC 48833DE1C7020001 CMP Q PTR [0042DAC8],00000001 DS:0042DAC8=00000024 -d .ÅÇÉÇîàÆÉø_wndproc 002B:0042DAC0 .ÅAPAMETPø_WNDPROC STRUCTURE 002B:0042DAC0 ..HWNDPR FIXED(63) 1771088 002B:0042DAC8 ..IMSG FIXED(63) 36 002B:0042DAD0 ..WPARAM FIXED(63) 0 002B:0042DAD8 ..LPARAM FIXED(63) 1374432 -
On tuossa ehkä jotain ongelmia, mutta pääosin ihan ok:
#include <iostream>
using namespace std;
#define start int main()
#define print(a,b,sep) cout<<a<<sep<<b<<endl;
#define end return 0;
start {
print("make",,,"")
end
}clang++ definetest.cpp
definetest.cpp:9:20: error: too many arguments provided to function-like macro invocation
print("make",,,"")
^
definetest.cpp:5:9: note: macro 'print' defined here
#define print(a,b,sep) cout<<a<<sep<<b<<endl;
^
definetest.cpp:9:5: error: use of undeclared identifier 'print'; did you mean 'printf'?
print("make",,,"")
^~~~~
printf
/usr/include/stdio.h:356:12: note: 'printf' declared here
extern int printf (const char *__restrict __format, ...);
^
definetest.cpp:9:10: error: expected ';' after expression
print("make",,,"")
^
;
definetest.cpp:9:5: warning: expression result unused [-Wunused-value]
print("make",,,"")
^~~~~Sitä paitsi nuo kaikki selittyy sillä, että käytti funktiota väärin. Jo toinen virheviesti (tai ensimmäinen note:) kertoo, mitä olisi pitänyt tehdä. Rivinumero on sitä paitsi oikein.
Siksi kysyin, että anna joku esimerkki, missä kääntäjäviesti on ruma makron typottamisen seurauksena.
No toki tämä on hieman ei-toivottu ja tarkoittaisi, ettei tuommoisia kannata välttämättä laittaa johonkin user facing input-kentän prosessointiin ilman tyyppitarkastuksia:
#include <iostream>
using namespace std;
#define start int main()
#define print(a,b,sep) cout<<a<<sep<<b<<endl;
#define end return 0;
start {
print("make",endl;cout<<2,"")
end
}Täällä oli jotain ongelmia https://stackoverflow.com/questions/14041453/why-are-preprocessor-macros-evil-and-what-are-the-alternatives, mutta en pitänyt mitään dramaattisena ja pidin niitä lähinnä user erroreina.
mavavilj kirjoitti:
Sitä paitsi nuo kaikki selittyy sillä, että käytti funktiota väärin. Jo toinen virheviesti (tai ensimmäinen note:) kertoo, mitä olisi pitänyt tehdä. Rivinumero on sitä paitsi oikein.
Siksi kysyin, että anna joku esimerkki, missä kääntäjäviesti on ruma makron typottamisen seurauksena.
Kokeile toteuttaa esikääntäjällä oikeasti uutta syntaksia, äläkä pelkästään korvaa muutamaa C-kielen avainsanaa koodissa.
Esimerkiksi PL/I:n esikääntäjällä voisin lisätä fibonacci komennon mikä käännösaikana tuottaisi taulukollisen fibonaccin lukuja:
%fibonacci: proc (n, table) statement;
dcl n fixed;
dcl table char;
dcl (i, f1, f2, f3) fixed;
dcl nums char;
f1 = 1; f2 = 0;
nums = '0';
do i = 1 to n;
f3 = f1 + f2;
f1 = f2;
f2 = f3;
nums = nums || ',' || f3;
end;
ans('dcl ' || table || ' (0:' || n || ') fixed bin init (' || nums || ');') skip;
%end fibonacci;
%act fibonacci;Käyttö ohjelmassa:
fibonacci n(20) table(fib);
tuossa siis n-parametri on taulukon yläindeksi ja table-parametri on haluttu nimi taulukolle.
Joo, paitsi, että yo. print()-esimerkki oli jo sinällään hyödyllisempi kuin C++:n oma versio.
mavavilj kirjoitti:
Joo, paitsi, että yo. print()-esimerkki oli jo sinällään hyödyllisempi kuin C++:n oma versio.
Yhäkään en ymmärrä, että miksi et käyttäisi vain normaalisti C/C++ kirjastoja pythonissasi.
//kirjasto.cpp
#include <iostream>
void Tulosta() {
std::cout<<std::endl;
}
template<typename First, typename ... Strings>
void Tulosta(First arg, const Strings&... rest) {
std::cout<<arg<<std::endl;
Tulosta(rest...);
}# testi.py
import ctypes
import pathlib
if __name__ == "__main__":
libname = pathlib.Path().absolute() / "kirjasto.so"
c_lib = ctypes.CDLL(libname)
c_lib.Tulosta("make","2")
c_lib.Tulosta("Rivi1","Rivi2","Rivi3")Koska FFI ei voi mitenkään tukea kaikkia kielen ominaisuuksia, vaan ainoastaan tiettyjä interface-ominaisuuksia, joissa menetetään koko kielen etu. Tähän ratkaisu on jo C++ Hour Glass API design pattern, mutta se on tosiaan FFI-kielelle eri asia kuin C++:lle.
mavavilj kirjoitti:
Koska FFI ei voi mitenkään tukea kaikkia kielen ominaisuuksia, vaan ainoastaan tiettyjä interface-ominaisuuksia, joissa menetetään koko kielen etu. Tähän ratkaisu on jo C++ Hour Glass API design pattern, mutta se on tosiaan FFI-kielelle eri asia kuin C++:lle.
On siinä toki rajoitteita, tai vähintään hommaa vähän riippuen mitä kirjaston funktioon pitää puskea. mutta ei sitä sen helpommaksi tee millään purkkaviritykselläkään, missä joudut joka tapauksessa kirjoittamaan C/C++:aa ja pythonia sekaisin, jos vaikka kirjasto edellyttää C++:n päässä vaikka std::ostreamiä.
Tuossa tapauksessa sinun pitää joko kirjoittaa sitä c++:aa suoraan, tai rakentaa oma mäpperi pythonin stream objektin ja std::ostream:in väliin, joka ei ole ihan triviaalia.
Ja jos nyt vaikka se Cython on mielestäsi oikea ratkaisu, niin joka tapauksessa on osattava sekä C++, Cython (joka kääntyy enivei C/C++:ksi), että Python. Joten todellisuudessa pärjäisit paremmin ihan valitsemalla joko C++:n tai Pythonin riippuen siitä, kummalle se tarve on. Sotkematta mukaan kolmatta kieltä.
groovyb kirjoitti:
Ja jos nyt vaikka se Cython on mielestäsi oikea ratkaisu, niin joka tapauksessa on osattava sekä C++, Cython (joka kääntyy enivei C/C++:ksi), että Python. Joten todellisuudessa pärjäisit paremmin ihan valitsemalla joko C++:n tai Pythonin riippuen siitä, kummalle se tarve on. Sotkematta mukaan kolmatta kieltä.
Tämän ketjun koko projektin tavoite on ollut jostain alusta alkaen tehdä Cython, joka on vain C++:aa, koska kuten itsekin tajusit, niin se on parempi kuin Cython. Cythonissa on kolme kieltä: C++, Python ja Cython-välikieli.
On intuitiivista, että Cythonin voi tehdä myös ilman Python runtimea eli esim. vain kirjoittamalla Python-likeä ja sitten kääntämällä sen C++:aan ennen kääntämistä.
mavavilj kirjoitti:
On intuitiivista, että Cythonin voi tehdä myös ilman Python runtimea eli esim. vain kirjoittamalla Python-likeä ja sitten kääntämällä sen C++:aan ennen kääntämistä.
Groovyb on varovasti yrittänyt kertoa sinulle, että tällöin menetetään myös kaikki Pythonin edut ja voitaisiin hyvin ohjelmoida pelkällä C++:lla.
jalski kirjoitti:
(21.02.2025 10:46:19): ”– –” Groovyb on varovasti yrittänyt kertoa sinulle...
En ole samaa mieltä.
Cythonihan on esimerkki jo siitä, että Python ei ole ongelmaton.
Lisäksi Cythonilla menetetään Pythonin edut:
https://cython.readthedocs.io/en/latest/src/
Lisäksi projektit pitää muokata Cythonille.
Koko high level -kielen skenaario tehdä ensin nopeasti huono runtime ja jälkeenpäin yrittää saada siitä nopea voidaan kiertää tekemällä vain staattinen kääntäjä C/C++:lle, jolloin mikään runtimessä, kääntäjässä yms. ei muutu. C/C++:lle tehdään vain ihmisille näkyvä erilainen representaatio.
Näin tekee myös https://github.com/linuxdeepin/unilang esim. https://github.com/linuxdeepin/unilang/blob/
Mutta myös Unilang tuo kehiin kolmannen kielen, jonka takia en alkanut käyttämään sitä.
Myös omassa ratkaisussasi kyse on kolmannesta kielestä, koska /#function systeemit eivät kuulu pythoniin, saati c++:n ominaisuuksien käyttäminen.
Se että käytät siitä termiä Python, ei muuta sitä sellaiseksi. Esimerkiksi C++ ja C# syntaksit ovat verrattain samanlaisia, mutta kieli ei ole sama. Koska kielen ominaisuudet ja toimintatapa ovat erilaisia.
Se mitä eniten tunnut kaipaavan on JVM tyyppistä ratkaisua, missä erilaisella notaatiolla ja syntaksilla voidaan tuottaa saman runtimen tukevaa koodia, kuten nyt vaikka Java/Kotlin/Clojure jotka pyörivät JVM:n päällä, tai C#/J#/F#/VB.Net jotka pyörivät samalla MS:n clr:n päällä.
Eli haet jotain Pythonin ja C++:n yhdistävää runtimea, jota voisi koodata haluamallasi kielellä.
groovyb kirjoitti:
(21.02.2025 10:55:16): Myös omassa ratkaisussasi kyse on kolmannesta...
Kumosin jo ne #-labelit.
Ei vaan haen sitä, jolla C++:n ekosysteemin voi valjastaa mihin tahansa syntaksiin. Tämä on myös Unilangin eräs kantava idea. C++:lle on yksinkertaisesti liikaa tärkeää koodia, joten on järkevintä käyttää sitä kaiken pohjana. Lisäksi tulee erottaa se, että onko syntaksi semanttisesti merkittävää (onko sillä myös eri merkitys) vai vain eri merkkijonoilla.
Oleellista ei siis ole, että onko jokin asia "pure Pythonia", vaan että onko se oleellisesti samankaltaista ollakseen yhtä produktiivista käyttää. Joo, tapa luoda kieliä JVM:lle on myös tätä.
Nykyinen ratkaisu katsoo joko makroja tai työkalua, joka osaa kääntää Clang-AST:eiden välillä syntaksista toiseen, jolloin Clang-AST on ikäänkuin tämä bytecode.
Joo mutta mikäpä estää, että C++ on "VM"? Sillä kuitenkin kirjoitetaan VM:jä, joten tottakai itse kielikin on Turingin kone.
Erityisesti:
https://stackoverflow.com/a/7321401
Löytyypä myös:
https://github.com/blackhole89/macros
Lisäksi kannattaa huomata, että C++ on joiltain osin jo yhtä tiivistä kuin Python, mutta toisaalla, kuten esim. printissä ei. Jos käyttää esim. auto:a aktiivisesti, niin sillä voi simuloida myös dynaamista tyypitystä.
Jos std::print ei kelpaa, sen kun käytät jotain kirjastoa josta tykkäät enemmän. Kannattaa pikku hiljaa siirtyä Hello Worldiä isompiin ohjelmiin eikä fiksaantua tähän.
mavavilj kirjoitti:
Jos käyttää esim. auto:a aktiivisesti, niin sillä voi simuloida myös dynaamista tyypitystä.
Miten? Eikö auto-tyypit päätellä staattisesti käännösaikana?
Esimerkiksi std::any on lähempänä dynaamista tyypitystä.
jlaire kirjoitti:
(21.02.2025 12:55:35): Jos std::print ei kelpaa, sen kun käytät jotain...
Osa kysymyksestä on myös hakuammuntaa siihen, että voisi muodostaa "simple C++" standardin, joka mukailee Pythonin etuja C++-kielessä. Jos ominaisuudet eivät ole standardikirjastossa tai jos niille ei ole vahvaa yhteisötukea, niin käyttämällä ko. kirjastoja vaan erottautuu niistä, jotka eivät käytä niitä, joten lisää käännöstyötä kirjastojen välillä. Standardilla voisi kuitenkin realistisesti luopua Pythonista kokonaan C++:n eduksi.
Tämän analysaattorin etu oli se, että se nimenomaan ei muokkaa standardia mitenkään toisin kuin esim. Unilang tai Cython, jotka tuottavat itse uuden standardin n+1. Se vain käyttää sitä eri muodossa. Lisäksi analysaattorin perustuessa joko clangiin tai makroihin analysaattoria käyttääkseen ei tarvitse asentaa mitään uutta dependencyä.
Analysaattorin C++- ja simple -moodeissa ei ole kääntäjän näkökulmasta mitään eroa, koska simple on vain näkymä C++:sta.
No preprocessorin rajoitteet tulikin nopeasti vastaan:
#include <iostream>
using namespace std;
#define def void *
#define ;} ;return nullptr;}
def test1(int v) {
cout << v << endl;
}
int main() {
test1(5);
return 0;
}---
No nyt minulla on tämmöinen idea aluilla:
#include <iostream>
#include <string>
#include <fstream>
using namespace std;
#define def void *
// https://stackoverflow.com/a/24315631
std::string ReplaceAll(std::string str, const std::string& from, const std::string& to) {
size_t start_pos = 0;
while((start_pos = str.find(from, start_pos)) != std::string::npos) {
str.replace(start_pos, from.length(), to);
start_pos += to.length(); // Handles case where 'to' is a substring of 'from'
}
return str;
}
// https://stackoverflow.com/a/116220
auto read_file(std::string_view path) -> std::string {
constexpr auto read_size = std::size_t(4096);
auto stream = std::ifstream(path.data());
stream.exceptions(std::ios_base::badbit);
if (not stream) {
throw std::ios_base::failure("file does not exist");
}
auto out = std::string();
auto buf = std::string(read_size, '\0');
while (stream.read(& buf[0], read_size)) {
out.append(buf, 0, stream.gcount());
}
out.append(buf, 0, stream.gcount());
return out;
}
// Python-style test function with def == void * and empty return so
// this program would replace return nullptr; to the end
def test1(int v) {
int e = 5;
}
int main() {
std::string file = read_file("./testfile.cpp");
std::ofstream out("output.cpp");
out << ReplaceAll(file, ";\n}", ";\nreturn nullptr;\n}");
out.close();
return 0;
}Korvataan kaikki ;\n} stringeihin eli palautumattomiin funktioihin return nullptr; loppuun. Jos funktio määriteltiin def, niin se kelpaa void *:lle.
Lisäksi, näytti, että funktiot eivät valita, jos on useampi return statement peräkkäin. Ts. vaikka ohjelma täyttäisi palauttaviinkin funktioihin return nullptr; niin tämä ei vaikuta toimintaan eikä tuota edes kääntäjävirheitä pl. main(), joka vaatii, että viimeinen lause on return joku_int.
Jos tämä toimii pitkällä tähtäimellä, niin on itseasiassa aika kivaa, että voi kirjoittaa funkioita, joissa on mikä tahansa paluuarvo, mutta tyypitetyt argumentit.
Ongelman voi ohittaa esim.:
// testfile.cpp
#include <iostream>
#include <string>
using namespace std;
#define def void *
def test1(int v) {
int e = v;
}
int main() {
cout << test1(5);
return 0;
// END
}jolloin outputina saadaan:
#include <iostream>
#include <string>
using namespace std;
#define def void *
def test1(int v) {
int e = v;
return nullptr;
}
int main() {
cout << test1(5);
return 0;
// END
}test1:n "simple"-versio oli siis:
def test1(int v) {
int e = v;
}Nyt kertokaa, miten void * returnin voi hajottaa siten, että noudattaa myös ohjeita eli tällaisen funktion tulee olla muotoa:
def func_name(typed_params) {
body_of_statements;
}jossa ei ole siis paluuarvoa.
#include <iostream>
#include <string>
using namespace std;
#define def void *
def test1(int v) {
int e = v;
}
def test2(int a, int b) {
auto c = test1(5);
return a+b+c;
}
int main() {
cout << test2(4,6);
return 0;
// END
}toimii vielä ihan hienosti. Virhe on:
output.cpp:16:15: error: arithmetic on a pointer to void
return a+b+c;
^~
1 error generated.mikä on täysin oikein, koska c on void *, koska test1 ei palauta mitään arvoa.
Sanottakoon, että tämä on "simple C++":n ominaisuus "Python-like functions".
Entä jos tekisi sellaisen expansionin, että antaisi kirjoittaa:
def func(a,b,c) {
body_of_statements;
}ja täydentäisi tämän analysaattorilla:
def func(std::any a, std::any b, std::any c) {
body_of_statements;
}Ehkä templateja kuitenkin?
Ja toki tällöin pitäisi muutenkin olla kyseessä funktio, jolle on mielekästä antaa erilaisia tyyppejä. Tässä kohdataan staattisen ja dynaamisen tyypityksen rajapinta. Se, että spesifioi tyypit säästää aikaa siinä, että ei tarvitse miettiä, miksi funktiot bugittavat, koska sinne pääsi sisään jotain, mitä ne eivät osaa käsitellä. Toisin kuin dynaamisissa kielissä, niin ei ole lopulta järkevää, että tyypit ovat dynaamisia, PAITSI KUN dynaamisuus erityisesti halutaan. Ohjelmoijan tulisi siis pyytää sitä erikseen.
Toisin sanoen, kun käytetään std::any tai kun ohjelmoija välttämättä haluaa dynaamiset tyypit, niin mahdollisia tyyppejä on kuitenkin aika vähän, mutta eipä tarvitse tehdä overloadeja:
Esimerkki:
void processValue(std::any value) {
if (value.type() == typeid(int)) {
int intValue = std::any_cast<int>(value);
std::cout << "Integer: " << intValue << std::endl;
} else if (value.type() == typeid(std::string)) {
std::string strValue = std::any_cast<std::string>(value);
std::cout << "String: " << strValue << std::endl;
}
}https://cppscripts.com/cpp-stdany
-> tämmöiselle funktiolle on paikka korvaamaan overloadien työläyttä ja sitä, että template on tuollaiselle liian laaja.
Siten voisi lisätä mahdollisuuden kirjoittaa
def func(a,b,c) {
body_of_statements;
}kun oletuksena on myös, että ohjelmoija käyttää tuollaista silloin kun parametrit saavat keskimäärin 1-3 mahdollista tyyppiä. Tällöin ohjelmoija myös kirjoittaa niiden tarkastukset funktion bodyyn.
Olkoon tämä sitten vaikka "Small Python-style dynamic function parameters".
Tyyppitarkastukset pitää tehdä Pythonissakin.
Jonkun kielimallin laitat tekemään tuota kääntö operaatiota.
wy5vn kirjoitti:
Jonkun kielimallin laitat tekemään tuota kääntö operaatiota.
? miksi
Tulevaisuus on täällä. Näin se vaan menee
Kannattaa tosiaan myös huomata, että nyt esim. Python-kirjastojen käyttäminen C++:sta vaatii enemmän vaivaa kuin että jos kirjasto olisi kuitenkin C++:lla, koska tyypit pitää muuntaa välissä. Siis vaikka C++:lla pääsee selvästi hyvin lähelle Pythonin käyttökokemusta.
Summa summarum:
“There are only two kinds of languages: the ones people complain about and the ones nobody uses.”
― Bjarne Stroustrup, The C++ Programming Language
Käyttääkö joku oikeasti c++:assa pythonilla tehtyjä kirjastoja. Tai no varmaan käyttää tyhmä kysymys. Kuulostaa vaan vähän hasardilta
mavavilj kirjoitti:
(21.02.2025 21:28:32): Kannattaa tosiaan myös huomata, että nyt esim...
Tätä ei kannattaisi nyt tuputtaa liikaa. En ole tarvinnut C++ koskaan VAIKKA se niin hieno kieli onkin. Mennääs nyt vaikka tässä järjestyksessä: Python, Java, whatever, jne., C++, C ja Brainfuck / (tai kenties joku random kieli).. Olen hieman laiska ja kaikkia kieliä en ole jaksanut opetella (vaikka maailma tarjoaa kaikkia hienoja kieliä!)...
wy5vn kirjoitti:
Käyttääkö joku oikeasti c++:assa pythonilla tehtyjä kirjastoja. Tai no varmaan käyttää tyhmä kysymys. Kuulostaa vaan vähän hasardilta
Aika paljon löytyy tutkimuspapereita, joissa demontraatio-toteutus on annettu Pythonilla. Joskus paperi on niin vaikea, että ei ole tehokasta portata sitä, ellei alkuperäinen authori portaa sitä. Alkuperäinen authori ei välttämättä ole koodari, joten todennäköisesti koodia ei portaa kukaan. Python on suosittu tutkijoilla ja erityisesti esim. koneoppimisessa, koska siinä on RAD (kuten sanoin monta viestiä sitten sen tärkeydestä) ja koska sen syntaksi muistuttaa pseudokoodia, joten on helppo liittää koodit ja pseudokoodit toisiinsa. Lisäksi nämä ovat monesti "pure Pythonia", eivätkä wrapattyä C/C++:saa. Siten algoritmi pitää joko portata C/C++:salle tai liittää Python C/C++:saan jotenkin.
Tässä on ihan ok chart:
https://www.ideamotive.co/hubfs/C vs Python-png.png
Tästä tulisi muuttaa vain kohtia
1 muuttuisi mikäli C++:lla olisi P:n ominaisuuksia
2 on edullisempi P:lle
3 on lähtökohtaisesti edullisempi C++:lle, mutta C++n tulisi antaa toteuttaa P:n versiota
4 on edullisempi P:lle
5 on makuasia
6 on subjektiivista
7 on edullisempi C++:lle
8 on edullisempi C++:lle
9 on edullisempi P:lle
10 riippuu käyttötarkoituksesta, mutta C++:n versio on robustimpi. C++:n tulisi sallia P:n versio optionaalisesti
11 muuttuisi mikäli C++:lla olisi P:n ominaisuuksia
12 muuttuisi mikäli C++:lla olisi P:n ominaisuuksia
13 on edullisempi C++:lle
14 on edullisempi C++:lle
15 muuttuisi mikäli C++:lla olisi P:n ominaisuuksia
16 muuttuisi mikäli C++:lla olisi P:n ominaisuuksia
-> Pythonilla on joitain vahvuuksia, mutta C++ on yleisesti parempi kieli. C++ voisi olla parempi, jos sillä olisi P:n jotkin ominaisuudet.
Kuten mielestäni implikoin aiemmin, historiallisesti olisi paljon hyödyllisempää, jos sen sijaan, että kehitetään n+1 kieli, niin jalostettaisiin aiempaan vain joku syntax translater uudelle syntaksille. Tällöin ekosysteemin voi kantaa mukana. Tämä idea on ties yhtä vanha kuin joku 50-luvun LISP.
"Thus, Lisp programs can manipulate source code as a data structure, giving rise to the macro systems that allow programmers to create new syntax or new domain-specific languages embedded in Lisp."
mavavilj kirjoitti:
Aika paljon löytyy tutkimuspapereita, joissa demontraatio-toteutus on annettu Pythonilla. Python on suosittu tutkijoilla ja erityisesti esim. koneoppimisessa, koska siinä on RAD (kuten sanoin monta viestiä sitten sen tärkeydestä) ja koska sen syntaksi muistuttaa pseudokoodia, joten on helppo liittää koodit ja pseudokoodit toisiinsa. Lisäksi nämä ovat monesti "pure Pythonia", eivätkä wrapattyä C/C++:saa. Siten algoritmi pitää joko portata C/C++:salle tai liittää Python C/C++:saan jotenkin.
Miksi näet koodin uusiksi kirjoittamisen toisella ohjelmointikielellä isoksi ongelmaksi? Minusta se voi olla jopa hyödyllistä ja auttaa ymmärtämään algoritmin toiminnan paremmin.
jalski kirjoitti:
(22.02.2025 10:23:39): ”– –” Miksi näet koodin uusiksi kirjoittamisen...
Koska käytännössä kukaan ei tee sitä, koska tutkija ei saa siitä mitään etua, koska tutkija saa rahaa tutkimuspaperista, eikä C++-koodista. Tutkijalle on siten edullista käyttää portausaika uuteen paperiin. Jos joku tekee portauksen, niin silloinkin sama työ tehdään kahteen kertaan.
Käsittääkseni FFI:eiden eräs syy on bisnes interest eli kuten JNI:n tapauksessa, niin yrityksille on kustannustehokasta päästä käyttämään jotain legacya, mutta samalla saavuuttaa etuja uudella kielellä. JNI:n idea ei ole, että Java on kuin C/C++:n superset, vaan idea on, että yritykset voivat käyttää legacyä, koska maksaisi liikaa kirjoittaa se Java:lle. Lähde esim. https://developer.ibm.com/articles/j-jni/
Moni muukin projekti tehdään Pythonilla tai JS:lla sen takia, että sen tekeminen C++:lla ei ole kustannustehokasta. Ts. se vain maksaisi enemmän rahaa vailla mitään selviä etuja. Seurauksena on kuitenkin eriytyneet ekosysteemit.
Joillain LISP:eillä ja esim. Haskellilla on vastaavankaltaisia kirjastoja tai koodeja. Nämä ovat usein tekoälypapereista, esim. NLP-algoritmeja.
Tässäkin tilanteessa voisi kuitenkin tunnistaa, että syy, miksi ne on LISP:eillä on, että se on lähes 1:1 mapping lambdakalkyylistä, mutta edelleen algoritmeista olisi hyötyä myös C++-ohjelmissa.
{kind=link}
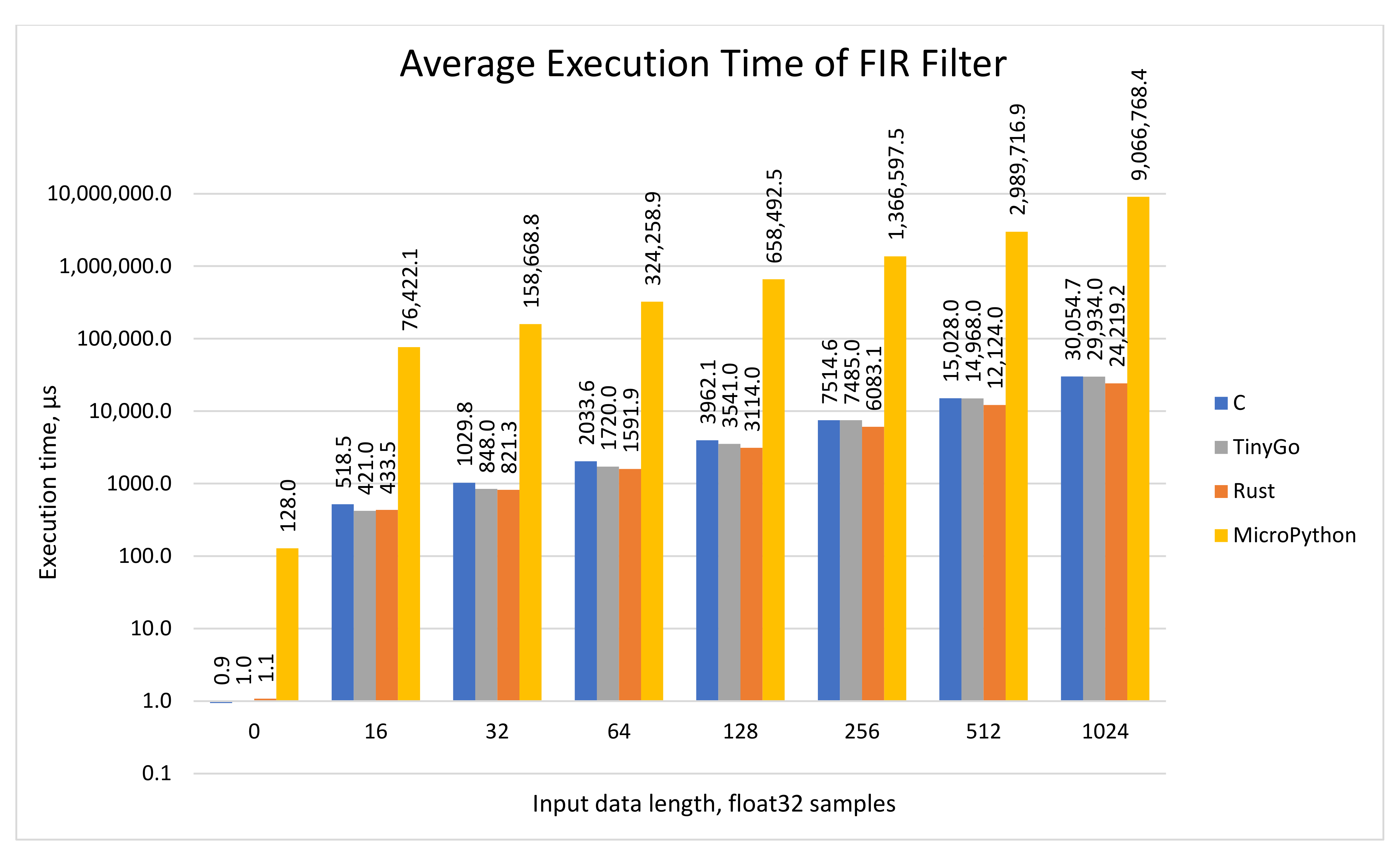{kind=link}
{kind=link}