En nyt ala mitään kummempia selittelemään, tässä koodi:
#include <iostream>
#include <ncurses.h>
int main() {
WINDOW *screen = initscr();
mvaddstr(2, 0, "´");
for(int i = 0; i < 5; ++i)
mvaddch(i, 5, '|');
getch();
endwin();
return 0;
}Tässä käännös:
g++ C++/ncurses_problem.cpp -o cpp -lncurses
Ja tässä tulos:
http://kuvauppi.fi/view/output/GUID/89D92F11-D94F-8C65-AF59-7EEE79048F4D/size/default/ncurses.png
Mitä voisin tehdä asialle?
Käyttöjärjestelmä on Ubuntu 10.04, ja sama tapahtui myös 9.04 versiollakin.
Edit: Unohtui mainita, että sama käy vaikka erikoismerkki olisi keskellä merkkijonoa, joten mvaddch:n käyttö ei käy tässä tilanteessa.
Syynä on se, että ncurses ei käsittele UTF-8-enkoodausta, jolloin kahden tavun kokoinen erikoismerkki sekoittaa laskut. Seuraava koodi toimii minulla oikein:
#include <curses.h>
#include <locale.h>
int main() {
setlocale(LC_CTYPE, "");
initscr();
mvprintw(0, 0, "%lc", L'ä'); mvprintw(0, 3, "|");
mvprintw(1, 0, "%ls", L"åäö"); mvprintw(1, 3, "|");
getch();
endwin();
}Leveyden määrittäminen formaattiin ("%13ls") ei valitettavasti näytä toimivan. Windowsissa pitää laittaa localeksi ".OCP", koodiin kirjoitettujen erikoismerkkien toimivuudesta en muista, mutta tuskin ainakaan samat UTF-8-muotoiset toimivat.
Kiitoksia, sain toimimaan. :)
Edit: Entäs miten tuo L"teksti" pitää laittaa kun käytetään muuttujia? Lmuuttuja ei tietenkään toimi.
Näköjään myös tämä toimii:
mvprintw(0, 0, "%s", "åäö");
Joka tapauksessa printw on oikea funktio. %ls-formaatille kelpaa wchar_t-merkeistä muodostuva teksti ja %lc-formaatille yksittäinen wchar_t. Joudut siis huomioimaan tämän ohjelmassasi ja käyttämään yleisesti charin sijaan wchar_t:tä (stringin sijaan wstringiä). %s-formaatille kelpaa tavallinen char-muotoinen teksti, joka on setlocalen määräämässä merkistössä (eli "":lla järjestelmän oletusmerkistössä); tällä pääset helpoimmalla, kunhan ei tule ongelmia eri oletusmerkistöjen kanssa. Onneksi UTF-8 alkaa olla Linuxin puolella standardi.
Sain toimimaan tuolla %ls-formaatilla kaikista parhaiten, mutta minulle jäi epäselväksi, että mitä tuo L tarkoittaa tuossa kirjoitettavan tekstin edessä, ja että kuinka se pitäisi kirjoittaa muuttujan kanssa?
(Olin edellisessä viestissäni vähän epäselvä, pahoittelen)
L'x' on wchar_t-tyyppinen merkki ja L"xyz" on wchar_t-merkeistä koostuva merkkijono, aivan kuten 'x' on char-tyyppinen merkki ja "xyz" on char-merkeistä koostuva merkkijono. (Ihan samalla tavalla myös 1.0f tarkoittaa float-tyyppistä lukua ja 1UL unsigned long -tyyppistä lukua.) L-merkki ei siis ole minkäänlainen maaginen muunnosoperaatio eikä sitä voi soveltaa muuttujiin. Juuri yllä selitin, mitä asialle pitää muuttujien kanssa tehdä. Toisin sanoen joudut ehkä kirjoittamaan merkittäviä osia ohjelmastasi uudestaan, jos haluat todella hyödyntää wchar_t:tä. Sen käyttö ei kuitenkaan aina ole mutkatonta (esim. tiedostojen kanssa), joten perehdy asiaan ja suunnittele hyvin.
Hmm, taidan sitten suosiolla jättää erikoismerkit pois ohjelmastani, sillä en juuri hoksannut muuta keinoa hoitaa asia kuin hillitön if-else if härdelli tai sitten pitäisi napata loopilla merkkijonosta erikoismerkit pois ja tulostaa ne erikseen... Tai no, toisaalta nykyään koneet alkavat olemaan sen verran tehokkaita että saattaisihan tuo onnistuakkin ilman suurempia kuormituksia.
Aihe on jo aika vanha, joten et voi enää vastata siihen.
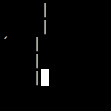{kind=link}